LabArchives Server
БесплатноНе проверенConnects AI assistants to LabArchives electronic lab notebooks, enabling querying, semantic search, page navigation, and file uploads with provenance tracking.

Описание
Connects AI assistants to LabArchives electronic lab notebooks, enabling querying, semantic search, page navigation, and file uploads with provenance tracking.
README
Tests License: MIT Python 3.11+ DOI codecov
Overview
A Model Context Protocol (MCP) server that connects AI assistants to LabArchives electronic lab notebooks (ELN). MCP is an open protocol that lets AI clients call external tools and data sources through structured requests. This server lets researchers query notebook records, search notebooks semantically, and integrate lab work into AI-assisted workflows.
Key Features:
- Agent Onboarding:
onboard()returns a structured lab overview, sticky context, and usage guidance - Semantic Search: Vector-based search across notebook content with metadata filters
- Read Access: List notebooks, navigate pages, read entries
- Persistent Context & Graphs: Project-scoped memory with NetworkX-backed graphs, related-page lookups, provenance tracing, and AI heuristics
- Linked-data Export: Export project provenance as JSON-LD aligned to PROV-O and schema.org
- AI Integration: Works with Claude Desktop, Windsurf, and any MCP client
- Secure: API key authentication with HMAC-SHA512 signing
- Reproducible: Conda-lock environment with pinned dependencies
Documentation
- Quick start:
docs/QUICKSTART.md - Agent configuration:
docs/agent_configuration.md - Onboarding payload reference:
docs/onboard_example.json - Onboarding walkthrough: see
docs/QUICKSTART.mdanddocs/agent_configuration.md - Upload API:
docs/upload_api.md - Graph concepts ("The Lab Brain"):
docs/graph_concepts.md - Linked-data provenance export:
docs/linked_data.md - Vector backend design and ops: docs/vector_backend.md
- Semantic governance:
docs/semantic_governance.md
Features
Implemented
- List all notebooks for a user
- Navigate notebook pages and folders
- Read page entries (text, headings, attachments)
- Semantic search across notebook content (vector search)
- Upload files with code provenance metadata
- Export project provenance graphs as PROV-O / JSON-LD
- Full HMAC-SHA512 authentication flow
🚧 Experimental
- Additional provenance enrichment and graph heuristics around upload workflows
🔮 Future
- Attachment downloads
- Advanced search filters
- Batch operations
Architecture
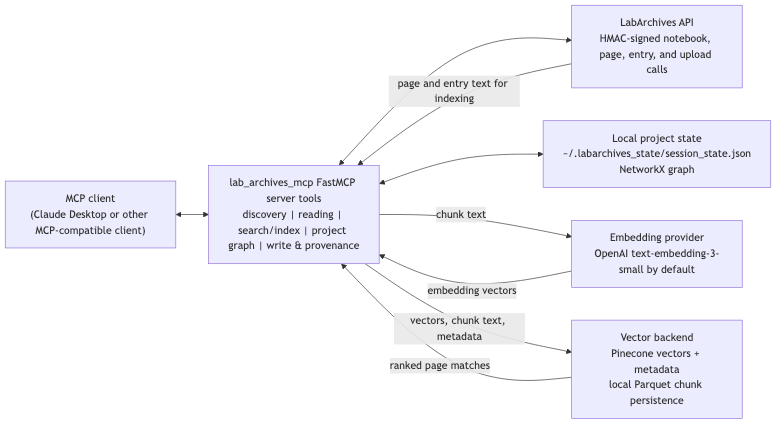
Figure: An MCP client calls the FastMCP server tools, which mediate LabArchives API access, local project-state updates, embedding requests, and vector-index reads and writes. Mermaid source and SVG are committed alongside the PNG under docs/figures/.
Language: Python.
Modules:
auth.py– credential loading, HMAC signing, UID resolution.eln_client.py– notebook navigation, page entry retrieval, upload orchestration.
models/upload.py– Pydantic contracts for uploads and provenance metadata.state/– persistent project contexts, graph construction, related-page heuristics, and next-step suggestions.linked_data/– JSON-LD export for legacy and enriched provenance graphs.transform.py– XML→JSON transforms and API fault translation.mcp_server.py– MCP server startup and FastMCP bootstrap.tools/– MCP tool handlers, shared decorators, and registry wiring.vector_backend/– semantic search indexing with Pinecone and local Parquet persistence; Qdrant is a placeholder extension point.
Linked-data Provenance Export
Project contexts can now be exported as JSON-LD using PROV-O for provenance semantics and schema.org for descriptive metadata.
labarchives-mcp export-provenance --project <project-id> --output graph.jsonld
python -m labarchives_mcp export-provenance --project <project-id> --output graph.jsonld
labarchives-mcp export-provenance --project <project-id> --output graph.ttl --format turtle
Install pip install -e ".[linked-data]" to enable Turtle and N-Quads CLI output. The MCP tool remains export_provenance_jsonld(project_id). See docs/linked_data.md for the vocabulary mapping and supported graph shapes.
Setup
1. Clone and Install
Method 1: As a Python module
git clone https://github.com/SamuelBrudner/lab_archives_mcp.git
cd lab_archives_mcp
2. Create Environment
Create the pinned Conda environment (local prefix):
conda-lock install --prefix ./conda_envs/labarchives-mcp-pol conda-lock.yml
Activate it:
conda activate ./conda_envs/labarchives-mcp-pol
Install git hooks and tooling:
pre-commit install
pre-commit install --hook-type commit-msg
3. Configure LabArchives Credentials
Copy the secrets template:
cp conf/secrets.example.yml conf/secrets.yml
Contact LabArchives support to request API access credentials. You'll need:
- Access Key ID (
akid) - Access Password (used for HMAC-SHA512 signature)
- API Region (e.g.,
https://api.labarchives.com)
Edit conf/secrets.yml and add your credentials:
LABARCHIVES_AKID: 'your_access_key_id'
LABARCHIVES_PASSWORD: 'your_api_password'
LABARCHIVES_REGION: 'https://api.labarchives.com'
OPENAI_API_KEY: 'sk-...'
PINECONE_API_KEY: 'your_pinecone_key'
PINECONE_ENVIRONMENT: 'us-east-1'
4. Obtain Your User ID (UID)
The LabArchives API requires a user-specific ID (uid) for all operations. You have two options:
Option A: Use Temporary Password Token (Recommended)
Log into your LabArchives notebook in the web browser
Navigate to Account Settings → Password Token for External Applications
Click to generate a temporary token (valid for 1 hour)
Copy the email and password token displayed
Run the helper script:
conda run -p ./conda_envs/labarchives-mcp-pol python scripts/resolve_uid.py redeem \ --email [email protected] \ --auth-code <paste_token_here>The script will print your UID. Copy it into
conf/secrets.yml:LABARCHIVES_UID: 'your_uid_value'
Option B: Browser-Based Login Flow
If you prefer the browser flow (or temporary tokens aren't working):
Generate a login URL:
conda run -p ./conda_envs/labarchives-mcp-pol python scripts/resolve_uid.py login-urlOpen the URL in your browser and complete the LabArchives sign-in
After redirect, extract the
auth_codefrom the URLRun the redeem command (same as Option A step 5)
Note: The UID is permanent for your account—once obtained, store it in conf/secrets.yml and you won't need to retrieve it again unless your LabArchives password changes.
5. Verify Setup
Test that everything works:
conda run -p ./conda_envs/labarchives-mcp-pol python -c "
from labarchives_mcp.auth import Credentials
from labarchives_mcp.eln_client import LabArchivesClient, AuthenticationManager
import httpx, asyncio
async def test():
creds = Credentials.from_file()
async with httpx.AsyncClient() as client:
auth = AuthenticationManager(client, creds)
uid = await auth.ensure_uid()
print(f'✓ UID verified: {uid}')
notebooks = await LabArchivesClient(client, auth).list_notebooks(uid)
print(f'✓ Retrieved {len(notebooks)} notebooks')
asyncio.run(test())
"
Requirements & limitations
LabArchives account and API access
- Full functionality (listing notebooks, reading pages, semantic search, upload with provenance) requires a LabArchives account and API token.
- The MCP server assumes that authentication has been configured via the documented environment variables and configuration files.
Optional external vector stores
- The semantic search and embedding layers can use external services such as OpenAI or Pinecone when configured.
- When these backends are enabled, text content and/or embeddings will be sent to the corresponding provider; institutions should review their data-governance policies before enabling them.
On-premise and open backends
- Qdrant, local embeddings, and fully on-premise vector search are extension points, not supported runtime paths in the current release.
- The current code raises
NotImplementedErrorforQdrantIndexandLocalEmbedding; deployments that need those paths must implement and review the corresponding backend before use.
Intended usage
lab_archives_mcpis designed as an integration layer between ELNs and AI assistants, not as a general-purpose ELN or standalone LIMS.- Production deployments should run behind institutional authentication and logging appropriate for research data.
FAIR & provenance
Reproducible environments
- Conda-lock files pin Python and dependency versions, enabling deterministic reconstruction of the MCP server environment.
- Continuous integration runs the test suite against these environments on multiple operating systems.
Provenance-aware uploads
- The upload tools capture rich code-provenance metadata, including:
git_commit_sha,git_branch,git_repo_url,git_is_dirty- Optional
code_versiontag executed_attimestamppython_versionand keydependencies- Operating system and (optionally) hostname
- This metadata is stored alongside the uploaded file in LabArchives, providing a durable link between notebook entries and the code that produced them.
- The upload tools capture rich code-provenance metadata, including:
Structured schemas
- All API payloads and configuration structures are defined using Pydantic models.
- This ensures explicit, versioned schemas for:
- LabArchives notebook and page representations
- Upload requests with provenance
- Server configuration, including vector backends
Data and code versioning
- The MCP server is intended to be used in conjunction with Git-based workflows (and optionally DVC or similar tools) so that raw data, processed data, and analysis code can be versioned in tandem with ELN entries.
Testing and continuous integration
- Unit tests and integration tests cover key functionality, including authentication, notebook navigation, and upload workflows.
- GitHub Actions runs the non-integration test suite with
pytest --cov=src --cov-report=xml --cov-report=term, writes the measured line coverage fromcoverage.xmlto the job summary, and attempts a non-blocking Codecov upload on the Ubuntu/Python 3.11 job. - The local revision run on Python 3.11 reported 262 passing non-integration tests, one skipped test (the
rdflib-gated linked-data round-trip case), six deselected integration tests, and 81% total line coverage. Use the Codecov badge for the current main-branch value.
Security
- The MCP server uses HMAC-SHA512 signing for authentication, with credentials stored securely in environment variables or configuration files.
- API keys and access tokens are never stored in plaintext or committed to version control.
Project state, graph navigation, and heuristics
- Persistent context: The server maintains project-scoped memory (visited pages, findings, linked notebooks) in
~/.labarchives_state/session_state.jsonby default so assistants can resume work across sessions and repositories. Projects are required—create one before logging visits or findings. - Graph-backed navigation: Page visits and findings are added to a NetworkX graph with project, notebook, page, and finding nodes, enabling related-page discovery (
get_related_pages) and provenance tracing (trace_provenance). - Project tools: Manage contexts with
create_project,list_projects,switch_project,delete_project, inspect them withget_current_context, and log observations vialog_finding. State is only persisted when a project is active. - Lightweight guidance:
suggest_next_stepsprovides cold start detection and activity stats (not prescriptive workflow phases). - Onboarding:
get_onboard_payload(orlabarchives-mcp --print-onboard) returns usage guidance and sticky context.
Agent Onboarding Workflow
- From the CLI, run
labarchives-mcp --print-onboard json(ormarkdown) to capture:- Server banner and purpose summary
- Recommended tool usage (
search_labarchives,list_notebook_pages,read_notebook_page) - Current lab notebook snapshot and sticky context block to persist in responses
- Persist the returned
sticky_contextin your agent memory before invoking other tools.
6. Captured MCP Tool Transcript
This transcript was captured by running the registered write_notebook_entry MCP tool in a local smoke harness with LabArchives network calls replaced by test doubles:
{
"call": {
"tool": "write_notebook_entry",
"arguments": {
"notebook_id": "NBID-demo",
"page_title": "QC note",
"content": "# QC note\n\nCaptured from local revision test.",
"content_format": "markdown"
}
},
"response": {
"page_tree_id": "page-42",
"entry_id": "entry-7",
"page_url": "https://mynotebook.labarchives.com/share/NBID-demo/page-42",
"created_at": "2026-05-24T21:45:00+00:00",
"part_type": "text entry"
}
}
Live LabArchives runs use the same tool call and return platform-generated page and entry identifiers.
7. Run the MCP Server
The server can be started in several ways:
# Method 1: As a Python module
conda run -p ./conda_envs/labarchives-mcp-pol python -m labarchives_mcp
# Method 2: Using the console script (after pip install -e .[dev])
conda run -p ./conda_envs/labarchives-mcp-pol labarchives-mcp
# Method 3: Direct Python (if environment is activated)
conda activate ./conda_envs/labarchives-mcp-pol
labarchives-mcp
The server runs in stdio mode and waits for MCP protocol messages. Press Ctrl+C to stop.
Connecting to AI Agents
The MCP server exposes LabArchives notebooks to AI agents via the MCP protocol.
For the most up-to-date configuration examples (Claude Desktop, Windsurf, generic MCP clients), see docs/agent_configuration.md. The snippets below are included for convenience.
For configuration examples for Windsurf and Claude Desktop (including environment variables and restart steps), see docs/agent_configuration.md.
Available Tools
Discovery:
list_labarchives_notebooks()- List all your notebookslist_notebook_pages(notebook_id)- Show table of contents for a notebook
Reading:
read_notebook_page(notebook_id, page_id, track_visit=True, dry_run=False)- Read content from a specific page and optionally record the visit in the active project
Search & index:
search_labarchives(query, limit=5)- Search indexed LabArchives notebooks semanticallysync_vector_index(force=False, dry_run=False, max_age_hours=None, notebook_id=None)- Plan or run a vector-index sync
Project state & graph:
create_project(name, description, linked_notebook_ids=None, dry_run=False)- Start and activate a project workspacelist_projects(),switch_project(project_id, dry_run=False),delete_project(project_id, dry_run=False)- Manage project contextslog_finding(content, source_url=None, page_id=None, dry_run=False)- Append a finding to the active project;page_idlinks the finding back to evidenceget_current_context()- Return full project state (pages, findings, graph)get_related_pages(notebook_id, page_id, limit=20, offset=0)- Find sibling/linked pages via the project graph and detected LabArchives links; returnsitemsplus paginationmetatrace_provenance(notebook_id, page_id, entry_id)- Trace sources and metadata for a specific entrysuggest_next_steps()- Get lightweight guidance based on your current project state (cold start vs active)export_provenance_jsonld(project_id)- Export a project graph as JSON-LD
Write & provenance:
write_notebook_entry(...)- Write a rich text entry directly to a LabArchives page, appending to an existing page or creating a page whenpage_idis omittedupload_to_labarchives(...)- Upload a file to LabArchives with code provenance metadata, creating a page and storing the file as page text or an attachment
The support tool get_onboard_payload(format="json") returns usage guidance and sticky context for MCP clients.
Indexing & Sync
- Semantic search operates over content that has already been indexed. Searches do not perform indexing implicitly.
- To index or refresh the vector database, use the MCP tool:
sync_vector_index(force=False, dry_run=False, max_age_hours=None, notebook_id=None)- The tool:
- Loads config from
conf/vector_search/default.yaml - Reads the persisted build record from
incremental_updates.last_indexed_file - Decides one of:
skipwhen config + embedding version match and the build is recentincrementalwhen the build is older thanmax_age_hours(only changed entries)rebuildwhen embedding version or config fingerprint changed, orforce=True
- Use
dry_run=Trueto return the plan without any side effects
- Loads config from
- Details of the build record and planning are documented in
docs/vector_backend.mdunder “Build Records” and “MCP Sync”.
Tool Schemas
list_labarchives_notebooks()
# Returns list of notebooks:
[{
"nbid": "MTU2MTI4NS43...", # Notebook ID
"name": "Mosquito Navigation",
"owner": "[email protected]",
"owner_name": "Example Owner",
"created_at": "1970-01-01T00:00:00Z",
"modified_at": "1970-01-01T00:00:00Z"
}]
list_notebook_pages(notebook_id, folder_id=None)
# Returns pages and folders:
[{
"tree_id": "12345",
"title": "Introduction",
"is_page": true, # Can contain entries
"is_folder": false
}, {
"tree_id": "67890",
"title": "Methods",
"is_page": false,
"is_folder": true # Contains sub-pages - use tree_id as folder_id to navigate
}]
# Navigate into a folder by passing its tree_id as folder_id:
list_notebook_pages(notebook_id, folder_id="67890")
read_notebook_page(notebook_id, page_id)
# Returns page content:
{
"notebook_id": "MTU2MTI4NS43...",
"page_id": "12345",
"entries": [{
"eid": "e789",
"part_type": "text_entry", # or "heading", "plain_text", "attachment"
"content": "<p>Entry text content...</p>",
"created_at": "2025-01-01T00:00:00Z",
"updated_at": "2025-01-02T08:30:00Z"
}],
"tracked_in_project": "Mosquito Navigation Review",
"tracked": true,
"dry_run": false
}
write_notebook_entry(...)
# Write Markdown directly to a page (creates a new page if page_id is omitted)
write_notebook_entry(
notebook_id="MTU2MTI4NS43...",
page_title="Protocol - 2025-10-02",
content="# Protocol\n\n- Step 1\n- Step 2",
content_format="markdown",
parent_folder_id="67890" # optional folder tree_id
)
# Append HTML to an existing page
write_notebook_entry(
notebook_id="MTU2MTI4NS43...",
page_id="12345",
content="<h2>Summary</h2><p>Results look promising.</p>",
content_format="html"
)
upload_to_labarchives(...) ⭐ NEW
See docs/upload_api.md for the complete API documentation and usage notes.
# Upload a file with code provenance metadata
# MANDATORY parameters:
upload_to_labarchives(
notebook_id="MTU2MTI4NS43...",
page_title="Analysis - 2025-09-30",
file_path="/path/to/analysis.ipynb",
git_commit_sha="a1b2c3d4...", # Full 40-char SHA
git_branch="main",
git_repo_url="https://github.com/user/repo",
python_version="3.11.8",
executed_at="2025-09-30T12:00:00Z",
dependencies={"numpy": "1.26.0", "pandas": "2.1.0"},
as_page_text=True # default: store contents as page text (set False for attachments)
)
# Returns:
{
"page_tree_id": "NEW_PAGE_ID",
"entry_id": "ENTRY_ID", # text entry or attachment EID
"page_url": "https://mynotebook.labarchives.com/...",
"created_at": "2025-09-30T12:00:00Z",
"file_size_bytes": 12345,
"filename": "analysis.ipynb"
}
```json
### Library Usage (Python)
```python
import asyncio
from datetime import datetime, UTC
from pathlib import Path
import httpx
from labarchives_mcp.auth import Credentials, AuthenticationManager
from labarchives_mcp.eln_client import LabArchivesClient
from labarchives_mcp.models.upload import UploadRequest, ProvenanceMetadata
async def main():
creds = Credentials.from_file() # reads conf/secrets.yml
async with httpx.AsyncClient(base_url=str(creds.region)) as http_client:
auth = AuthenticationManager(http_client, creds)
client = LabArchivesClient(http_client, auth)
uid = await auth.ensure_uid()
# A) Render Markdown → HTML as page text (recommended for .md)
md_req = UploadRequest(
notebook_id="NBID...",
page_title="Protocol - 2025-10-02",
file_path=Path("protocol.md"),
metadata=ProvenanceMetadata(
git_commit_sha="a" * 40,
git_branch="main",
git_repo_url="https://github.com/user/repo",
git_is_dirty=False,
executed_at=datetime.now(UTC),
python_version="3.11.8",
dependencies={"numpy": "1.26.0"},
os_name="Darwin",
hostname=None,
),
create_as_text=True,
)
result = await client.upload_to_labarchives(uid, md_req)
print("Page:", result.page_url)
# B) Keep file as attachment (e.g., .ipynb)
nb_req = UploadRequest(
notebook_id="NBID...",
page_title="Analysis - 2025-10-02",
file_path=Path("analysis.ipynb"),
metadata=md_req.metadata,
create_as_text=False,
)
result = await client.upload_to_labarchives(uid, nb_req)
print("Page:", result.page_url)
asyncio.run(main())
```python
> **🔒 Security Note**: The upload tool is enabled by default. For production deployments or shared environments, **disable write capabilities** by setting `LABARCHIVES_ENABLE_UPLOAD=false` in the environment configuration above. This prevents AI assistants from unintentionally modifying your research records.
#### Example Scope
The captured transcript above is the repository-maintained tool example. Notebook names, page IDs, and entry IDs are institution-specific, so conversational examples with invented notebook contents are intentionally omitted.
---
## Troubleshooting
### "The supplied signature parameter was invalid" (Error 4520)
This means the API signature computation failed. Common causes:
- Wrong `LABARCHIVES_PASSWORD` in secrets file
- Incorrect method name (should omit class prefix, e.g., `user_access_info` not `users:user_access_info`)
- Clock skew between your machine and LabArchives servers
### "404 Not Found" on API endpoints
- Verify `LABARCHIVES_REGION` is correct for your institution
- Confirm with LabArchives support that your access key has the required API methods enabled
- Check that you're using `/api/` paths (not `/apiv1/` or `/api/v1/`)
### Cannot generate or redeem UID
- Ensure you have API access credentials from LabArchives support
- Try the temporary password token method (Option A) first
- If browser-based flow fails with 404, contact LabArchives to enable callback URLs for your key
### MCP Server Won't Start
- Verify `LABARCHIVES_UID` is set in `conf/secrets.yml`
- Run the verification script (step 5 of setup) to test credentials
- Inspect stderr output for Loguru messages, or configure a Loguru file sink if you need persistent logs
---
## Usage (Example)
### List notebooks
```json
{
"resource": "labarchives:notebooks",
"list": [
{
"nbid": "12345",
"name": "Fly Behavior Study",
"owner": "[email protected]",
"owner_email": "[email protected]",
"owner_name": "Example Owner",
"created_at": "2025-01-01T12:00:00Z",
"modified_at": "2025-01-02T08:30:00Z"
}
]
}
## API Schema
The API contract is defined by **Pydantic models** (single source of truth):
- **Configuration**: `Credentials` in `src/labarchives_mcp/auth.py`
- **Resources**: `NotebookRecord` in `src/labarchives_mcp/eln_client.py`
Generate JSON Schema for API documentation:
```bash
# Notebook resource schema
conda run -p ./conda_envs/labarchives-mcp-pol python -c "
from labarchives_mcp.eln_client import NotebookRecord
import json
print(json.dumps(NotebookRecord.model_json_schema(), indent=2))
"
# Configuration schema
conda run -p ./conda_envs/labarchives-mcp-pol python -c "
from labarchives_mcp.auth import Credentials
import json
print(json.dumps(Credentials.model_json_schema(), indent=2))
"
All field descriptions, examples, and validation rules are in the Pydantic models. No separate YAML/JSON schema files—code is the source of truth.
Development Notes
- Fail loud and fast on errors (invalid signature, uid expired, etc.).
- No silent fallbacks—errors must propagate as structured MCP errors.
- Core LabArchives requests run directly through
httpx.AsyncClient; add external throttling if your deployment demands rate limits beyond the platform defaults. - The MCP server does not currently cache
epoch_timeorapi_base_urls; extendAuthenticationManagerif you need those optimisations.
Versioning & Release Management
See CONTRIBUTING.md for versioning, Conventional Commits, and release steps.
Use this citation policy consistently:
- Software concept DOI: https://doi.org/10.5281/zenodo.17728440
- JORS resubmission archive:
v0.5.1, version DOI https://doi.org/10.5281/zenodo.20421457, Git tag https://github.com/SamuelBrudner/lab_archives_mcp/releases/tag/v0.5.1 - Previous v0.5.0 archive (superseded by v0.5.1 for doc-only fixes): version DOI https://doi.org/10.5281/zenodo.20421239
- Original submission archive (historical traceability):
v0.3.2, version DOI https://doi.org/10.5281/zenodo.17772522
The DOI badge, CITATION.cff primary identifier, and codemeta.json
identifier use the concept DOI. The README BibTeX and CITATION.cff
preferred citation point to the v0.5.1 resubmission archive; the BibTeX
doi field will be updated to the version-specific DOI after Zenodo
deposit. The v0.5.0 and v0.3.2 DOIs are retained for historical traceability only.
Contributing
We welcome contributions! See CONTRIBUTING.md for:
- Development setup instructions
- Code style guidelines
- Testing procedures
- Pull request process
Citation
If you use this software in your research, please cite:
@software{brudner2026labarchives,
author = {Brudner, Samuel N.},
title = {LabArchives MCP Server: AI Integration for Electronic Lab Notebooks},
year = {2026},
doi = {10.5281/zenodo.20421457},
url = {https://doi.org/10.5281/zenodo.20421457},
version = {0.5.1}
}
License
This project is licensed under the MIT License - see the LICENSE file for details.
Acknowledgments
- Built on the Model Context Protocol by Anthropic
- Uses FastMCP framework
- LabArchives API documentation and support
Установка LabArchives Server
У этого сервера нет опубликованного пакета — он собирается из исходников. Открой репозиторий и следуй инструкции в README.
▸ github.com/SamuelBrudner/lab_archives_mcpFAQ
LabArchives Server MCP бесплатный?
Да, LabArchives Server MCP бесплатный — установка в пару кликов через Unyly без оплаты.
Нужен ли API-ключ для LabArchives Server?
Нет, LabArchives Server работает без API-ключей и переменных окружения.
LabArchives Server — hosted или self-hosted?
Self-hosted: сервер запускается локально на твоей машине командой из раздела установки.
Как установить LabArchives Server в Claude Desktop, Claude Code или Cursor?
Открой LabArchives Server на unyly.org, выбери вкладку своего клиента (Claude Desktop, Claude Code, Cursor) и нажми Install — конфиг сгенерируется автоматически, без правки JSON.
Похожие MCP
Fetch
Web content fetching and conversion for efficient LLM usage.
AWS KB Retrieval
Retrieval from AWS Knowledge Base using Bedrock Agent Runtime.
 автор: modelcontextprotocol
автор: modelcontextprotocolSpring AI MCP Server
Provides auto-configuration for setting up an MCP server in Spring Boot applications.
llm-analysis-assistant
A very streamlined mcp client that supports calling and monitoring stdio/sse/streamableHttp, and can also view request responses through the /logs page. It also
 автор: xuzexin-hz
автор: xuzexin-hzCompare LabArchives Server with
Не уверен что выбрать?
Найди свой стек за 60 секунд
Автор?
Embed-бейдж для README
Похожее
Все в категории ai