loading…
en/
Browse all
Thumbgate
FreeMaintainedThumbGate self-improving agent governance: thumbs-up/down turns every mistake into a prevention rule and blocks repeat patterns. 33 pre-action checks, budget en

About
ThumbGate self-improving agent governance: thumbs-up/down turns every mistake into a prevention rule and blocks repeat patterns. 33 pre-action checks, budget enforcement, and self-protection for Claude Code, Cursor, Codex, Gemini CLI, and Amp.
README
![]()
AI coding agents repeat mistakes — and one wrong tool call can wipe a directory, leak a key, or push broken code.
ThumbGate is the local-first firewall for AI coding agents. It runs in the PreToolUse hook on your machine and blocks dangerous tool calls — rm -rf, secret exfiltration, off-scope edits, a bad git push — before they execute, across Claude Code, Cursor, Codex, Gemini, Amp, Cline, and OpenCode. No server, no gateway. (Regulated-industry policy templates — legal intake, financial compliance, healthcare — build on the same engine.)
The product is a self-improving enforcement layer: thumbs-down feedback, prompt evaluation, and proof from prior runs become prevention rules that permanently stop repeated failures before the next tool call.
Agent tries: rm -rf tests/
ThumbGate: ⛔ BLOCKED — "Never delete test directories"
Pattern matched: rm.*-rf.*tests
Source: your thumbs-down from last Tuesday
Tokens spent on this repeat: 0
npx thumbgate init # auto-detects your agent, wires hooks, 30 seconds
Works with Claude Code, Cursor, Codex, Gemini CLI, Amp, Cline, OpenCode and any MCP-compatible agent. Free tier: 5 feedback captures/day (25 total) and up to 3 active auto-promoted prevention rules. Pro: $19/mo or $149/yr — unlimited rules, history-aware lessons, feedback sessions, dashboard, DPO export. Enterprise (custom pricing, scoped after intake) adds a shared hosted lesson DB, org dashboard, and shared org-wide enforcement.
"A better dashboard doesn't make the agents more reliable. The hard part isn't visibility. It's trust."
— Rob May, CEO & co-founder, Neurometric AI, quoted in The New Stack on Anthropic's Claude Code Agent View (May 2026).
ThumbGate is the open-source layer that makes the trust part real: PreToolUse gates, thumbs-down to rule, audit trail on every interception.
Agentic development cycle fit
Agentic development is becoming a loop: Guide → Generate → Verify → Solve. ThumbGate gives that loop a hard execution boundary.
- Guide: standards, prior thumbs-downs, and approval policies become concrete context.
- Generate: Claude Code, Cursor, Codex, Gemini, Amp, Cline, OpenCode, and MCP agents keep producing plans and tool calls.
- Verify: risky actions need evidence before execution, not just after PR review.
- Solve: blocked failures become reusable lessons, shared prevention rules, DPO exports, and audit events.
In that stack, ThumbGate is the pre-action gate between generated intent and executed action.
Discoverable slash-commands — the guardrail layer for spec-driven agents
Spec-driven agent frameworks like GSD (get-shit-done) and GitHub Spec Kit are great at planning and generating work — they expose dozens of discoverable /gsd-* / /specify commands in the agent command palette. ThumbGate is the guardrail layer for spec-driven agents: it sits after the plan, on the boundary between a generated tool call and its execution. It works alongside GSD / Spec-Kit, not instead of them — they decide what to build; ThumbGate enforces what the agent must never do while building it.
npx thumbgate init installs these commands into your agent's palette (.claude/commands/, .gemini/commands/, .antigravitycli/commands/) so the enforcement layer is as browsable as the planning layer:
| Command | What it does | Wraps (existing capability) |
|---|---|---|
/thumbgate-guard |
Turn the last agent mistake into a hard prevention rule | capture_feedback + thumbgate force-gate |
/thumbgate-rules |
List the active prevention rules + lessons guarding this repo | prevention_rules, get_reliability_rules, search_lessons |
/thumbgate-blocked |
Show what's actually been blocked — gate stats + enforcement matrix | gate_stats, enforcement_matrix |
/thumbgate-protect |
Show branch/release governance; grant a scoped, expiring approval | get_branch_governance, approve_protected_action |
/thumbgate-doctor |
Health-check the wiring (hooks, MCP, agent-readiness) | thumbgate doctor |
Each is a thin wrapper over an existing MCP tool or CLI command — no new enforcement logic, just discoverability.
🎬 90-second demo
Watch the force-push scenario: agent tries to git push --force, one thumbs-down, next session it's blocked — zero tokens spent on the repeat.
▶ Watch the 90-second demo · Script · ElevenLabs narration: npm run demo:voiceover
First-dollar activation path
If someone is not already bought into ThumbGate, do not lead with architecture. Lead with one repeated mistake.
- Show the pain: open the ThumbGate GPT and paste the bad answer, risky command, deploy, PR action, or agent plan before it runs again.
- Capture the lesson: type
thumbs down:orthumbs up:with one concrete sentence. Native ChatGPT rating buttons are not the ThumbGate capture path; typed feedback is. - Enforce the repeat: run
npx thumbgate initwhere the agent executes so the lesson can become one of your Pre-Action Checks instead of another reminder. - Upgrade only after proof: Solo Pro is for the dashboard, DPO export, proof-ready evidence, and higher capture limits after one real blocked repeat. Team starts with the Workflow Hardening Sprint around one repeated failure, one owner, and one proof review.
The buying question is simple: what repeated AI mistake would be worth blocking before the next tool call?
The Problem — the bill nobody talks about
Frontier-model calls are not cheap. Sonnet 4.5 is ~$3 / 1M input tokens and ~$15 / 1M output tokens. Opus is 5× that. Every time your agent:
- hallucinates a function name and you have to correct it,
- retries the same failing tool call until it gives up,
- regenerates a 4,000-token plan you already approved last session,
- repeats a destructive command you blocked manually yesterday,
…you are paying for that round-trip. Twice if it retries. Three times if you re-prompt. And the agent has no memory across sessions, so the meter resets every Monday.
Session 1: Agent force-pushes to main. You fix it. +4,200 tokens
Session 2: Agent force-pushes again. You fix it. +4,200 tokens
Session 3: Same mistake. Again. You lose 45m. +5,800 tokens
That's ~$0.21 in tokens just to fix the same mistake three times — multiplied by every developer, every repeated-mistake class, every week. The math gets ugly fast.
The Solution — fix it once, the bill never sees it again
Session 1: Agent force-pushes to main. You 👎 it. +4,200 tokens
Session 2: ⛔ Check blocks the force-push. Zero round-trip. +0 tokens
Session 3+: Never happens again. +0 tokens
One thumbs-down. The PreToolUse hook intercepts the call before it reaches the model — no input tokens, no output tokens, no retry loop. The dashboard tracks tokens saved this week as a live counter so you can see exactly what your prevention rules are worth. Mark a review checkpoint once, and the dashboard narrows the next pass to only the feedback, lessons, and check blocks that landed since your last review.
ThumbGate doesn't make your agent smarter. It makes your agent cheaper to be wrong with.
🧠 The Context Brain
Every coding agent starts each session amnesiac — it has no memory of the mistakes it made yesterday, the fixes your team already rejected, or the rules this repo enforces. So it repeats them, and you pay for it again.
ThumbGate gives your repo a context brain: a single, versioned, agent-readable artifact that consolidates everything the agent should know before it acts — the lessons it has learned, the guardrails it must not cross, the gates that are enforced, and the project's own instruction files.
npx thumbgate brain --write # → .thumbgate/BRAIN.md
Then point your agent at it — add Read .thumbgate/BRAIN.md first to your CLAUDE.md / AGENTS.md, and every Claude Code, Codex, Cursor, or Gemini CLI session boots with your repo's institutional memory already loaded. The output is deterministic, so BRAIN.md lives in git and only changes when the underlying memory does — review it like any other file.
# ThumbGate Context Brain
## What this codebase taught its agents (lessons)
- ⛔ Force-pushing to main was rejected — use --force-with-lease on feature branches only
## Guardrails — do NOT repeat these (prevention rules)
- Never run DROP on production tables
## Active enforcement (gates)
- `DROP.*production` → block
Same idea the SEO world is now calling a "client brain" — persistent context that AI reads before doing the work — applied to engineering: the institutional memory that stops your coding agent from relearning the same lesson on your dime.
Quick Start
npx thumbgate init # auto-detects your agent, wires everything
npx thumbgate capture down "Never run DROP on production tables"
That single command creates a prevention rule. Next time any AI agent tries to run DROP on production:
⛔ Check blocked: "Never run DROP on production tables"
Pattern: DROP.*production
Verdict: BLOCK
Architecture
ThumbGate operates as a 4-layer enforcement stack between your AI agent and your codebase:
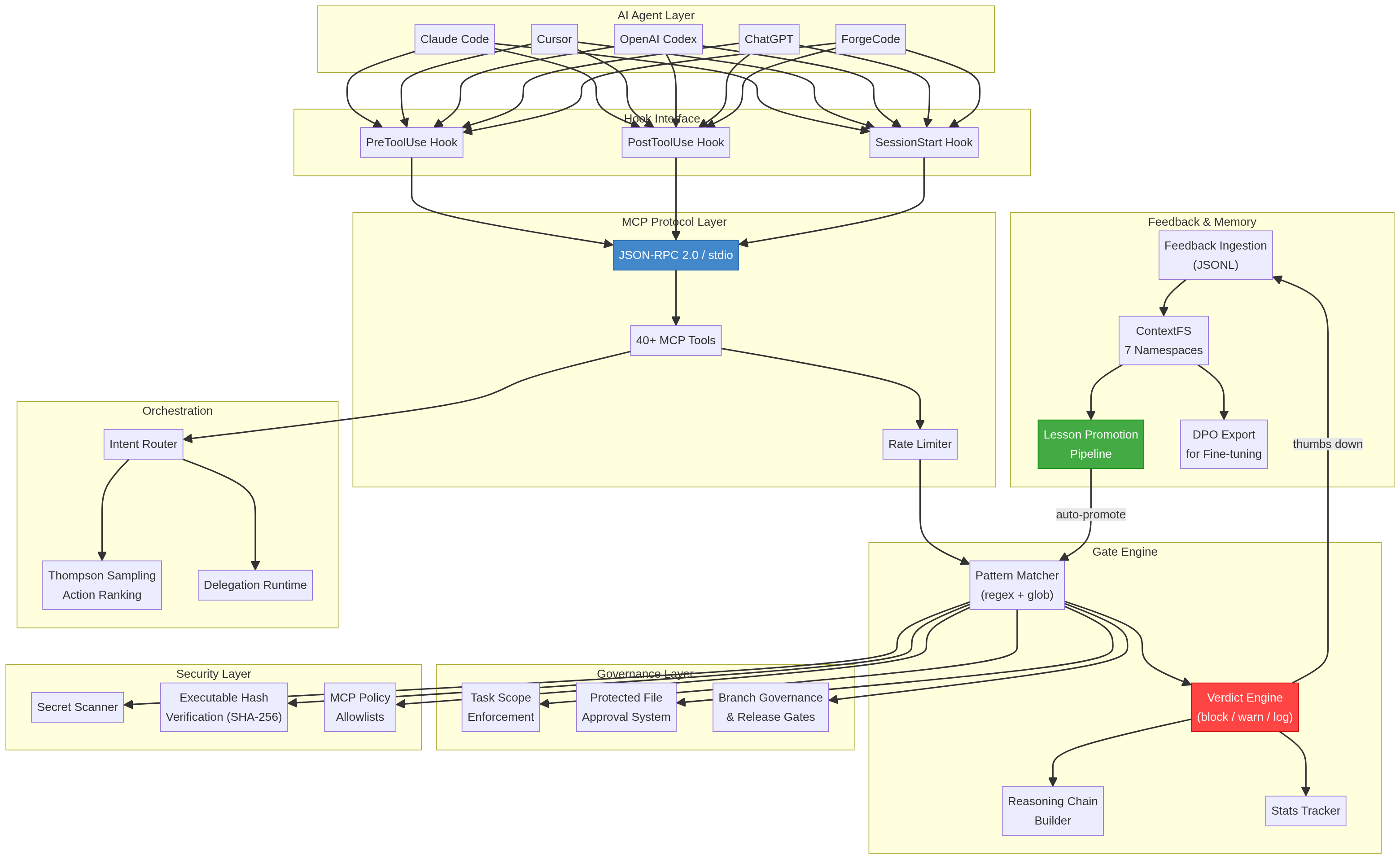
Layer 1: Feedback Capture
Your thumbs-up/down reactions are captured via MCP protocol, CLI, or the ChatGPT GPT surface. Each reaction is stored as a structured lesson with context, timestamp, and severity.
Layer 2: Check Engine
The check engine converts lessons into enforceable rules. The runtime gate decision is deterministic — literal pattern match → AST match → scoped rule lookup. No LLM call on the enforcement path.
Where retrieval is needed (an agent is about to run a destructive command not on the literal block list, but semantically similar to one we've blocked before), ThumbGate uses local CPU-only bge-small embeddings via LanceDB's built-in pipeline. No external API call, no inference cost beyond CPU. So "no LLM in enforcement" holds: the gate decision uses no LLM; the rule corpus is just searchable via local embeddings.
Thompson Sampling tunes per-rule confidence weights for soft-gating rules so high-noise rules quiet down and high-signal rules sharpen. It never decides whether a rule fires — a hard rule like "block git push --force on main" always fires deterministically. Bandit exploration would be terrifying for hard rules; we don't do it.
Rules stay in local ThumbGate runtime state.
Layer 3: Pre-Action Interception
Before any agent action executes, ThumbGate's PreToolUse hook intercepts the command and evaluates it against all active checks. This happens at the MCP protocol level — the agent physically cannot bypass it.
Layer 4: Multi-Agent Distribution (the actual moat vs hand-rolled hooks)
Claude Code already ships permissions.deny and PreToolUse hooks. Cursor and Codex have their own. So why ThumbGate over a hand-written hook?
Two things hand-written hooks structurally cannot do:
- Cross-agent propagation. A
permissions.denypattern lives in one agent's config and stays there. ThumbGate's checks distribute across every connected agent over MCP stdio — thumbs-down once in Cursor, the same pattern blocks on Claude Code, Codex, Gemini CLI, Cline, OpenCode, Amp in the next session, no copy-paste between configs. - Learning loop. A hand-written hook covers exactly the patterns you wrote. ThumbGate promotes every thumbs-down into a fresh rule, tunes existing rules' confidence weights from outcomes (Thompson Sampling, see Layer 2), and pulls semantically-near patterns into scope via local embeddings. The rule corpus sharpens without an operator hand-writing a regex for every new mistake shape.
Hand-rolled hooks are the right tool for a small, static denylist you maintain by hand. ThumbGate is the right tool when you want corrections from any agent to harden every agent automatically.
Prompt engineering still matters, but it is only the starting point. ThumbGate adds prompt evaluation on top: proof lanes, benchmarks, and self-heal checks tell you whether your prompt and workflow actually held up under execution instead of leaving you to guess from vibes. Run npx thumbgate eval --from-feedback --write-report=.thumbgate/prompt-eval-proof.md to turn real thumbs-up/down feedback into reusable eval cases and a buyer-ready proof report.
Retrieval & latency: local-first, zero network hops
ThumbGate's latency advantage is structural, not a tuned cloud cluster: there is no retrieval service and no model on the enforcement path, so the gate decision never leaves your machine.
flowchart LR
A["Agent about to run<br/>a tool call"] --> B{"Literal / AST match<br/>on an active rule?"}
B -- "exact match" --> D["Deterministic gate decision<br/>(no model, on-device)"]
B -- "no exact match, but<br/>semantically near a<br/>blocked pattern" --> C["Local CPU embeddings<br/>bge-small via LanceDB<br/>(no external API)"]
C --> D
D -- "known-bad" --> E["⛔ BLOCK before execution"]
D -- "safe" --> F["✓ Allow"]
- Deterministic first. Most decisions are a literal or AST pattern match against your active rules — sub-millisecond, on-device, no embeddings.
- Local semantic fallback. When an action isn't on the literal block list but is semantically near one you've blocked before, ThumbGate searches the rule corpus with CPU-only
bge-smallembeddings via LanceDB — still local, still no external API call. - No LLM on the enforcement path. The gate never calls a model to decide block/allow. Thompson Sampling only tunes soft-rule confidence weights; hard rules always fire deterministically (see Layer 2).
The fastest network round-trip is the one you never make: enforcement is fully local, so it adds negligible latency to the agent loop — no cloud retrieval, no inference hop, no data leaving the machine.
Managed model benchmark lane
When a new managed model drops, do not swap ThumbGate over on vendor claims alone. Rank it against the actual ThumbGate workload first:
npx thumbgate model-candidates --workload=pretool-gating --json
npx thumbgate model-candidates --workload=long-trace-review --provider=openai-compatible --gateway=tinker --json
The catalog currently includes the April 23, 2026 Tinker additions:
tinker/qwen3.6-35b-a3bfor pre-action gating, agentic coding, and tool-usetinker/qwen3.6-27bfor the cheap fast-pathtinker/kimi-k2.6-128kfor long-trace review and multi-agent sessions
Each recommendation ships with the benchmark commands to run next: feedback-derived prompt eval, gate-eval, and thumbgate bench. For whole-repo clone claims, add npx thumbgate bench --programbench-smoke to generate a ProgramBench-style cleanroom proof report without claiming an official ProgramBench score. That keeps model selection evidence-backed instead of hype-driven.
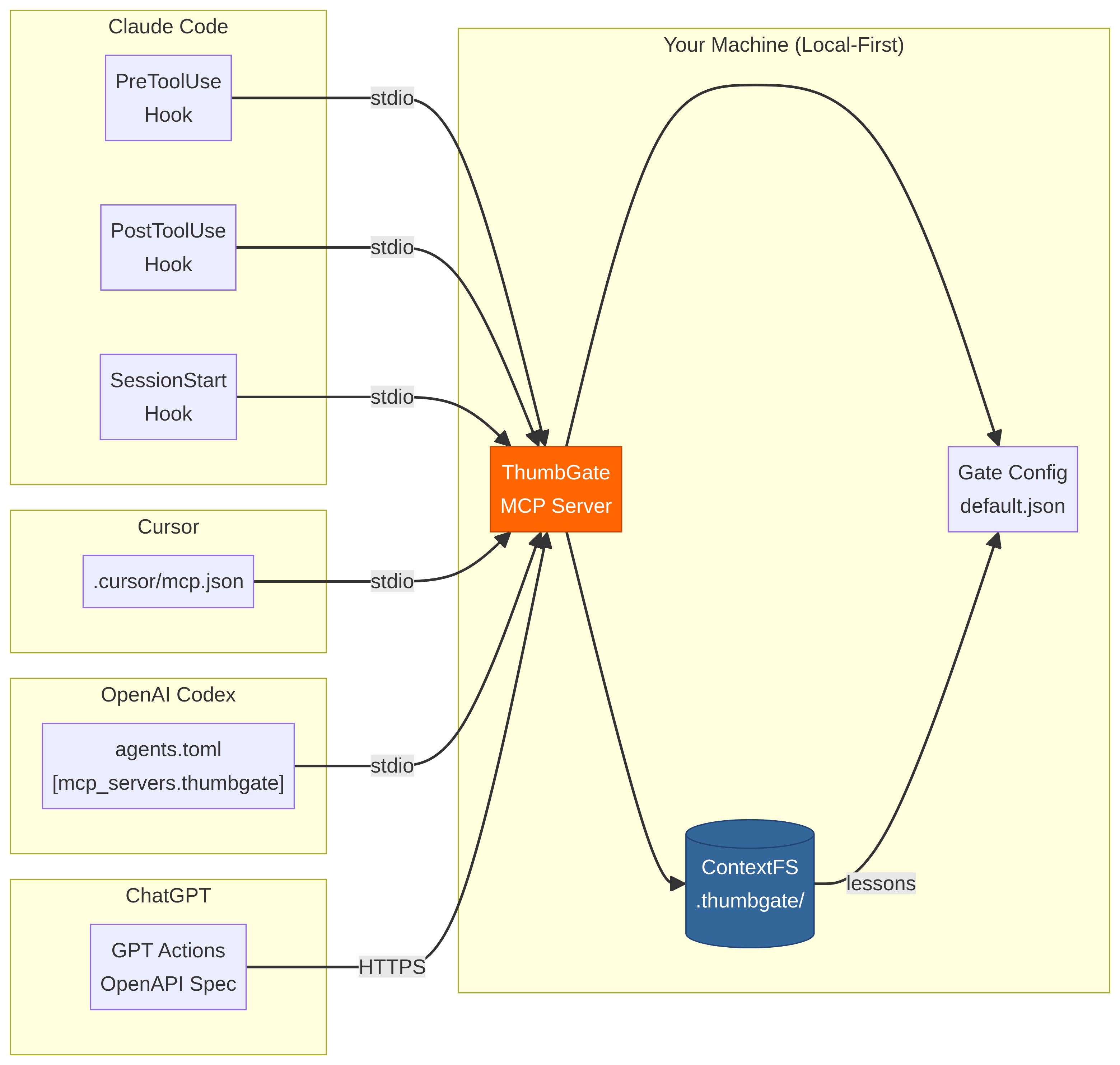
Install for Your Agent
| Agent | Command |
|---|---|
| Claude Code | npx thumbgate init --agent claude-code |
| Cursor | npx thumbgate init --agent cursor |
| VS Code / Open VSX | plugins/vscode-extension/README.md |
| Antigravity-compatible | plugins/antigravity-extension/INSTALL.md |
| JetBrains | plugins/jetbrains-plugin/README.md |
| Codex | npx thumbgate init --agent codex |
| Gemini CLI | npx thumbgate init --agent gemini |
| Amp | npx thumbgate init --agent amp |
| Cline (Roo Code successor) | npx thumbgate init --agent cline |
| Claude Desktop | Download extension bundle |
| Any MCP agent | npx thumbgate serve |
Works with Claude Code, Cursor, Codex, Gemini CLI, Amp, Cline, OpenCode, and any MCP-compatible agent. Migrating from Roo Code (sunsetting 2026-05-15)? See adapters/cline/INSTALL.md.
Install scope: machine-wide vs per-project
ThumbGate supports two install scopes. Pick once when you install — you can switch later by re-running with the other flag.
| Scope | Command | Settings file | Lesson DB + dashboard live in | When to use |
|---|---|---|---|---|
| Machine-wide (default) | npx thumbgate init |
~/.claude/settings.json |
~/.claude/memory/feedback/ |
Solo dev — one shared dashboard across every repo on this machine. A lesson learned in repo-A blocks the same mistake in repo-B automatically. |
| Per-project | npx thumbgate init --project (in the repo root) |
<repo>/.claude/settings.json |
<repo>/.claude/memory/feedback/ |
Client work, compliance, or multi-tenant — separate dashboard per repo, lessons stay isolated, audit trail belongs to the repo. |
Both scopes write mcpServers.thumbgate + the PreToolUse / UserPromptSubmit / PostToolUse / SessionStart hooks; the only difference is where. Machine-wide is the right default for most developers. Switch to --project only when you have a reason to keep lessons from bleeding between repos.
Per-project lesson DBs live under each repo's
.claude/memory/feedback/and must stay gitignored — they're a runtime store, not source. ThumbGate's bundled.gitignoretemplate handles this.
Status bar proof


Claude renders the live ThumbGate footer today. npx thumbgate init --agent codex now installs the full Codex hook bundle and writes the ThumbGate statusLine target into ~/.codex/config.json so you can test it on your local Codex build immediately.
Install Codex Plugin
Open the Codex plugin install page or download the standalone bundle from GitHub Releases. The Codex launcher resolves thumbgate@latest when MCP and hooks start, so published npm fixes reach active Codex installs without hand-editing ~/.codex/config.toml.
- Install page: thumbgate.ai/codex-plugin
- Direct zip: thumbgate-codex-plugin.zip
- Follow: plugins/codex-profile/INSTALL.md
Install ChatGPT App / GPT Action
ChatGPT is the advice, checkpointing, and typed-feedback surface; ThumbGate's hard enforcement still runs locally in Codex, Claude Code, Cursor, Gemini CLI, Amp, OpenCode, MCP, or CI after install.
- App page: thumbgate.ai/chatgpt-app
- Live GPT: thumbgate.ai/go/gpt
- GPT Action schema: thumbgate.ai/openapi.yaml
- Follow: adapters/chatgpt/INSTALL.md
How It Works
STEP 1 STEP 2 STEP 3
──────── ──────── ────────
You react ThumbGate learns The check holds
👎 on a bad ──► Feedback becomes ──► Next time the
agent action a saved lesson agent tries the
and a block rule same thing:
👍 on a good ──► Good pattern gets ⛔ BLOCKED
agent action reinforced (or ✅ allowed)
No manual rule-writing. No config files. Your reactions teach the agent what your team actually wants.
ThumbGate sells three concrete outcomes:
- Prevent expensive AI mistakes — catch bad commands, destructive database actions, unsafe publishes, and risky API calls before they run.
- Make AI stop repeating mistakes — fix it once, turn the lesson into a rule, and block the repeat before the next tool call lands.
- Turn AI into a reliable operator — move from a smart assistant that apologizes after damage to a production-ready operator with checkpoints, proof, and enforcement.
- Measure prompts instead of rewriting them blindly — use
thumbgate eval --from-feedback, proof lanes, ThumbGate Bench, andself-heal:checkto evaluate whether prompts and workflows actually improved behavior.
Use Cases
Developer Workflows
- Stop force-push to main — Check blocks
git push --forceon protected branches before it runs - Prevent repeated migration failures — Each mistake becomes a searchable lesson that fires before the next attempt
- Block unauthorized file edits — Control which files agents can touch with path-based rules
- Memory across sessions — The agent remembers your feedback from yesterday
- Shared team safety — One developer's thumbs-down protects the whole team
- Auto-improving without feedback — Self-improvement mode evaluates outcomes and generates rules automatically
Enterprise & Regulated Industries
- Legal AI intake governance — Block unauthorized practice of law (ABA Rule 5.5), require conflict-of-interest clearance before fact collection (Rules 1.7/1.9/1.10), prevent privileged content from leaving firm boundaries (Rule 1.6)
- Financial compliance — Gate AI-generated trade recommendations, block unauthorized disclosures, enforce approval chains before customer-facing outputs
- Healthcare — Prevent AI agents from providing medical diagnoses, enforce HIPAA-compliant data routing, require clinician review before patient-facing content
- Audit trail — Every gate decision (block, allow, reroute) is preserved with rule version, timestamp, and reviewer path for compliance review
Built-in Checks
⛔ force-push → blocks git push --force
⛔ protected-branch → blocks direct push to main
⛔ unresolved-threads → blocks push with open reviews
⛔ package-lock-reset → blocks destructive lock edits
⛔ env-file-edit → blocks .env secret exposure
+ custom prevention rules for project-specific failures
CLI Reference
npx thumbgate init # detect agent, wire hooks
npx thumbgate doctor # health check
npx thumbgate capture up|down "<text>" # capture a signal as a stored lesson (positional format)
npx thumbgate lessons # see what's been learned
npx thumbgate brain --write # build .thumbgate/BRAIN.md — the agent-readable context brain
npx thumbgate explore # terminal explorer for lessons, checks, stats
npx thumbgate background-governance # review background-agent run risk
npx thumbgate model-candidates --workload=dashboard-analysis --provider=openai --json # evaluate GPT-5.5 routing
npx thumbgate native-messaging-audit # inspect local browser bridges and extension hosts
npx thumbgate dashboard --open # open local project-scoped dashboard in browser
thumbgate-dashboard # standalone browser dashboard shortcut (run '/project:thumbgate-dashboard' in Claude/Grok)
npx thumbgate serve # start MCP server on stdio
npx thumbgate bench # run reliability benchmark
npx thumbgate bench --programbench-smoke # include cleanroom whole-repo proof lane
npx thumbgate break-glass --reason="ThumbGate over-fired" # short TTL recovery for gate over-fire
Recovery if a gate over-fires
ThumbGate should block repeated unsafe actions, not trap the operator. If a noisy rule or stale memory pattern blocks the hook/settings change you need to recover, open a short-lived break-glass window:
npx thumbgate break-glass --reason="ThumbGate over-fired and blocked operator recovery"
What this unlocks for up to 5 minutes:
- Edits to
.claude/settings.local.json,.claude/settings.json,.codex/config.toml, and the same files inside nested workspaces. - The short-lived proof gates used for PR recovery:
pr_create_allowedandpr_threads_checked.
What stays gated:
- Force pushes, protected-branch pushes, broad
rm -rf, unsafechmod, package publishes/releases, and local-only remote side effects. - Arbitrary protected files such as
README.md,AGENTS.md, policy bundles, or credentials.
Verify the recovery window and runtime health before continuing:
npx thumbgate break-glass --reason="verify recovery path" --json
npx thumbgate doctor
If you change MCP or hook settings, restart the affected agent session so Claude Code, Cursor, Codex, or another runtime reloads .mcp.json and local settings.
Pricing
| Free | Pro ($19/mo) | Enterprise | |
|---|---|---|---|
| Local CLI + enforced checks | ✅ | ✅ | ✅ |
| Feedback captures | 5/day (25 total) | Unlimited | Unlimited |
| Active auto-promoted prevention rules | 3 | Unlimited | Unlimited |
| MCP agent integrations | All | All | All |
| Personal dashboard | — | ✅ | ✅ |
| DPO export (model fine-tuning) | — | ✅ | ✅ |
| Lesson export/import | — | ✅ | ✅ |
| Shared hosted lesson DB | — | — | ✅ |
| Org-wide dashboard | — | — | ✅ |
| Approval + audit proof | — | — | ✅ |
| Regulatory gate templates | — | — | ✅ |
| Custom policy layers (firm/practice-area) | — | — | ✅ |
| Compliance audit export | — | — | ✅ |
| Dedicated onboarding + SLA | — | — | ✅ |
The free tier gives you 5 feedback captures/day (25 total) and up to 3 active auto-promoted prevention rules — enough to make ThumbGate part of your daily flow before you upgrade. MCP integrations for all agents (Claude Code, Cursor, Codex, Gemini, Amp, Cline, OpenCode) ship free.
Pro ($19/mo or $149/yr) removes the rule cap and adds history-aware lesson recall, lesson search, DPO export, and a personal dashboard. Enterprise (custom pricing, scoped after intake) adds a shared hosted lesson DB, org dashboard, and shared enforcement across the org, plus regulatory gate templates (legal intake, financial compliance, healthcare), custom policy layers scoped to firm/practice-area, compliance audit export, and dedicated onboarding with SLA.
Best first paid motion for teams: the Workflow Hardening Sprint — qualify one repeated failure before committing to a full rollout. Start intake →
Best first technical motion: install the CLI-first and let init wire hooks for the agent you already use.
Paid path for individual operators: ThumbGate Pro is the self-serve side lane for a personal dashboard and export-ready evidence.
Start free · See Pro · Team Sprint intake
Team Lesson Sharing (Pro + Team)
One team's hard-won lessons shouldn't stay trapped on one laptop. ThumbGate Pro and Team can export lessons as portable bundles and import them into any other ThumbGate instance — so a mistake caught by Team A becomes a prevention rule for Team B.
Export lessons from one project:
curl -X POST http://localhost:3456/v1/lessons/export \
-H "Authorization: Bearer $THUMBGATE_API_KEY" \
-H "Content-Type: application/json" \
-d '{"outputPath": "./lessons-export.json"}'
Filter by signal or tags:
curl -X POST http://localhost:3456/v1/lessons/export \
-H "Authorization: Bearer $THUMBGATE_API_KEY" \
-H "Content-Type: application/json" \
-d '{"signal": "down", "tags": ["push-notifications", "ci"]}'
Import into another team's ThumbGate:
curl -X POST http://localhost:3456/v1/lessons/import \
-H "Authorization: Bearer $THUMBGATE_API_KEY" \
-H "Content-Type: application/json" \
-d @lessons-export.json
What happens on import:
- Deduplication — lessons with the same ID or title+signal are skipped
- Provenance tracking — every imported lesson is tagged
team-importwith original source project, export timestamp, and original ID - No overwrite — import is additive; existing lessons are never modified
The export bundle includes full lesson metadata: signal, title, context, tags, failure type, skill, structured rules, and diagnosis. It's the same data you see in the lesson detail dashboard — portable as JSON.
Use cases:
- Share enforcement patterns across repos in the same org
- Onboard a new team with pre-built lessons from a mature project
- Export lessons before a project handoff so institutional knowledge transfers
- Feed lessons from multiple teams into a centralized DPO training pipeline
DPO Export for Fine-Tuning (Pro + Team)
Every thumbs-up and thumbs-down becomes a training signal. ThumbGate Pro exports your captured feedback as DPO (Direct Preference Optimization) pairs — ready to feed into a LoRA fine-tune so your model stops repeating known mistakes at the weight level, not just the check level.
Export DPO pairs:
curl -X POST http://localhost:3456/v1/dpo/export \
-H "Authorization: Bearer $THUMBGATE_API_KEY" \
-o dpo-pairs.jsonl
What you get: JSONL where each line is a preference pair:
chosen— the agent action you thumbed uprejected— the action you thumbed down for the same task contextprompt— the originating user intent
Use cases:
- Fine-tune Llama 3 / Mistral / local models with a LoRA adapter trained on your real mistakes
- Feed into RLAIF or KTO pipelines (KTO export also available via
/v1/kto/export) - Build a model that natively avoids your team's known failure patterns — no check at inference time needed
Why this matters: Checks block mistakes. Fine-tuning prevents them from being attempted. Combine both for belt-and-suspenders governance.
Tech Stack
| Layer | Technology |
|---|---|
| Storage | SQLite + FTS5, LanceDB vectors, JSONL logs |
| Capture | 5/day, 25 total on Free; unlimited on Pro, Team, and Enterprise |
| Intelligence | MemAlign dual recall, Thompson Sampling |
| Enforcement | PreToolUse hook engine, Checks config |
| Interfaces | MCP stdio, HTTP API, CLI (Node.js >=18) |
| Billing | Stripe |
| Execution | Railway, Cloudflare Workers, Docker Sandboxes |
| Governance | Workflow Sentinel, control plane, Docker Sandboxes |
Every Changeset is tied to the exact main merge commit and generates Verification Evidence for Release Confidence.
Popular buyer questions: AI search topical presence · Relational knowledge and AI recommendations · Background agent governance · GPT-5.5 model evaluation · Stop repeated AI agent mistakes · Browser automation safety · Native messaging host security · Autoresearch agent safety · Cursor guardrails · Codex CLI guardrails · Gemini CLI memory + enforcement · Google Cloud MCP guardrails · Roo Code alternative: migrate to Cline
Conversational ad / AI-search answer assets: AI Mode ads for agent governance · MCP tool governance · AI agent pre-action approval gates
Workflow Hardening Sprint · Live Dashboard
Integrations
- ChatGPT App / GPT Action — First-class ChatGPT distribution page with the live GPT, public OpenAPI Action schema, and local enforcement install path
- Open ThumbGate GPT — ThumbGate GPT: start here. Paste agent actions, get advice + checkpointing. No, users do not have to keep chatting inside the ThumbGate GPT to use ThumbGate — the hard enforcement layer still runs where the work happens.
- Claude Desktop Extension — One-click install for Claude Desktop
- Codex Plugin — Auto-updating standalone bundle and install page for Codex CLI
- VS Code / Open VSX Extension — Marketplace-ready MCP provider and
.vscode/mcp.jsonfallback for VS Code-compatible IDEs - Antigravity-compatible VSIX — Open VSX/direct VSIX install path while Antigravity-specific marketplace support is still unproven
- JetBrains Plugin Scaffold — IntelliJ/PyCharm Marketplace path for the same
thumbgate@latestruntime - Perplexity Command Center — AI-search visibility + lead discovery
- ThumbGate Bench — Reliability benchmark and ProgramBench-style cleanroom proof lane
- Manus AI Skill — ThumbGate integration for Manus AI agents
Feedback Sessions
Give the agent more context when a thumbs-down isn't enough:
👎 thumbs down
└─► open_feedback_session
└─► "you lied about deployment" (append_feedback_context)
└─► "tests were actually failing" (append_feedback_context)
└─► finalize_feedback_session
└─► lesson inferred from full conversation
Free and self-hosted users can invoke search_lessons directly through MCP, and via the CLI with npx thumbgate lessons. History-aware feedback sessions give the agent full context for each lesson.
Enterprise Data Chat and Optional Google Adapters
The Enterprise dashboard chat is local/open-source first: it answers over local ThumbGate data using lesson retrieval, LanceDB-backed vectors, and your configured LLM. Set THUMBGATE_LOCAL_LLM_ENDPOINT to an OpenAI-compatible local endpoint (Ollama, llama.cpp, vLLM, LM Studio, etc.) when you want generated answers without sending dashboard data to Google.
Google Cloud is an optional regulated-enterprise adapter, not a dashboard chatbot requirement. If a buyer already standardizes on Vertex AI or Dialogflow CX, ThumbGate can verify that posture and deploy guard adapters in their tenancy.
Optional Vertex Setup
To wire local ThumbGate scoring to Vertex AI, run:
npx thumbgate setup-vertex
- Auto-Discovery: Automatically detects your active authenticated
gcloudsession and active project ID. - Auto-Enablement: Programmatically enables the Vertex AI API in your project.
- Auto-Configuration: Writes local Vertex routing settings to your
.envfile.
This command does not create or verify a live Dialogflow CX agent. Dialogflow is only relevant when a customer wants ThumbGate guard adapters in front of their own production DFCX agents. On current Google Cloud CLI installs, the old alpha gcloud CX command group is not available; verify Conversational Agents / Dialogflow CX with the Google Cloud console or the official Dialogflow CX REST API (projects.locations.agents) before claiming a live DFCX deployment.
Zero-Friction Cost Containment ($10/mo Hard Cap)
Google Cloud budget alerts are "alert-only" and do not stop API traffic, risking unexpected bill shock. ThumbGate completely resolves this on the client side:
- Instant Shutdown: ThumbGate maintains a lightweight, local token ledger and instantly halts outgoing API traffic the millisecond your monthly token spending approaches the $10 limit (500k tokens of Gemini 1.5 Flash).
- Bypasses extra shutdown plumbing: Requires no Pub/Sub or Cloud Functions for the local ThumbGate-side stop condition. You still need normal Google Cloud billing/API setup and live-agent verification for DFCX pilots.
FAQ
Is ThumbGate a model fine-tuning tool? No. ThumbGate does not update model weights. It captures feedback, stores lessons, injects context at runtime, and blocks bad actions before they execute.
How is this different from CLAUDE.md or .cursorrules? Those are suggestions the agent can ignore. ThumbGate checks are enforced — they physically block the action before it runs. They also auto-generate from feedback instead of requiring manual writing.
Does it work with my agent? If it supports MCP or pre-action hooks, yes. Claude Code, Claude Desktop, Cursor, Codex, Gemini CLI, Amp, Cline, OpenCode all work out of the box.
Is it free? The free tier gives you 5 feedback captures/day, 25 total captures, and up to 3 active auto-promoted prevention rules — enough for solo devs to prove a blocked repeat before upgrading. MCP integrations ship free for every agent.
Pro ($19/mo or $149/yr) removes the rule cap and adds history-aware lesson recall, lesson search, and a personal dashboard. Enterprise (custom pricing, scoped after intake) adds a shared hosted lesson DB, org dashboard, and shared enforcement.
Docs
- ThumbGate for Federal Agencies — pilot-ready posture, NIST 800-53 control mapping, OMB M-24-10 / EO 14110 alignment, ThumbGate-Core gov deployment mode, public/Core boundary invariants. Landing page: thumbgate.ai/federal.
- First Dollar Playbook — turning one painful workflow into the next booked pilot
- Commercial Truth — pricing, claims, what we don't say
- Goal Contracts — evidence-before-done contracts for multi-agent handoffs
- Changeset Strategy — release notes and version bump enforcement
- Release Confidence — changesets, version checks, proof lanes
- Verification Evidence — proof artifacts
- Claude Desktop Extension Guide
- Agent Workflow Contract — the agent-run contract for all ThumbGate operations
- Ready for Agent Intake — ready-for-agent intake template
- SEO Guide: Claude Code Guardrails
- Unsupervised Learning Signals — silent-failure clustering (on by default as of 2026-05-21; opt out via
THUMBGATE_SILENT_FAILURE_CLUSTERING=0; only meaningfully active on workspaces with ≥ 50 tool calls/day) - ThumbGate-Core — private core for hosted overlays, ranking, policy synthesis, billing intelligence, and org/team workflows
License
MIT. See LICENSE.
How to install
Run in your terminal:
claude mcp add thumbgate -- npx -y thumbgate
