loading…
Browse all
Anchor
Freea self-hostable Java/Spring Boot service for source-grounded chunk validation and three-agent deliberation (proposer / critic restricted to macro view / synthes

About
a self-hostable Java/Spring Boot service for source-grounded chunk validation and three-agent deliberation (proposer / critic restricted to macro view / synthesiser). Differentiator vs the existing entries: lets you analyse and audit papers you've ingested rather than just searching external sources. Apache 2.0, BYO OpenAI-compatible LLM.
README
RAG that knows when its source disagrees with itself. Source-grounded chunk validation + three-agent deliberation, in one Spring Boot service. Speaks REST, MCP, and Java / Python / Node SDKs.
Built by Enzo Reyes. v0 in progress — see SPEC.md for the full design.
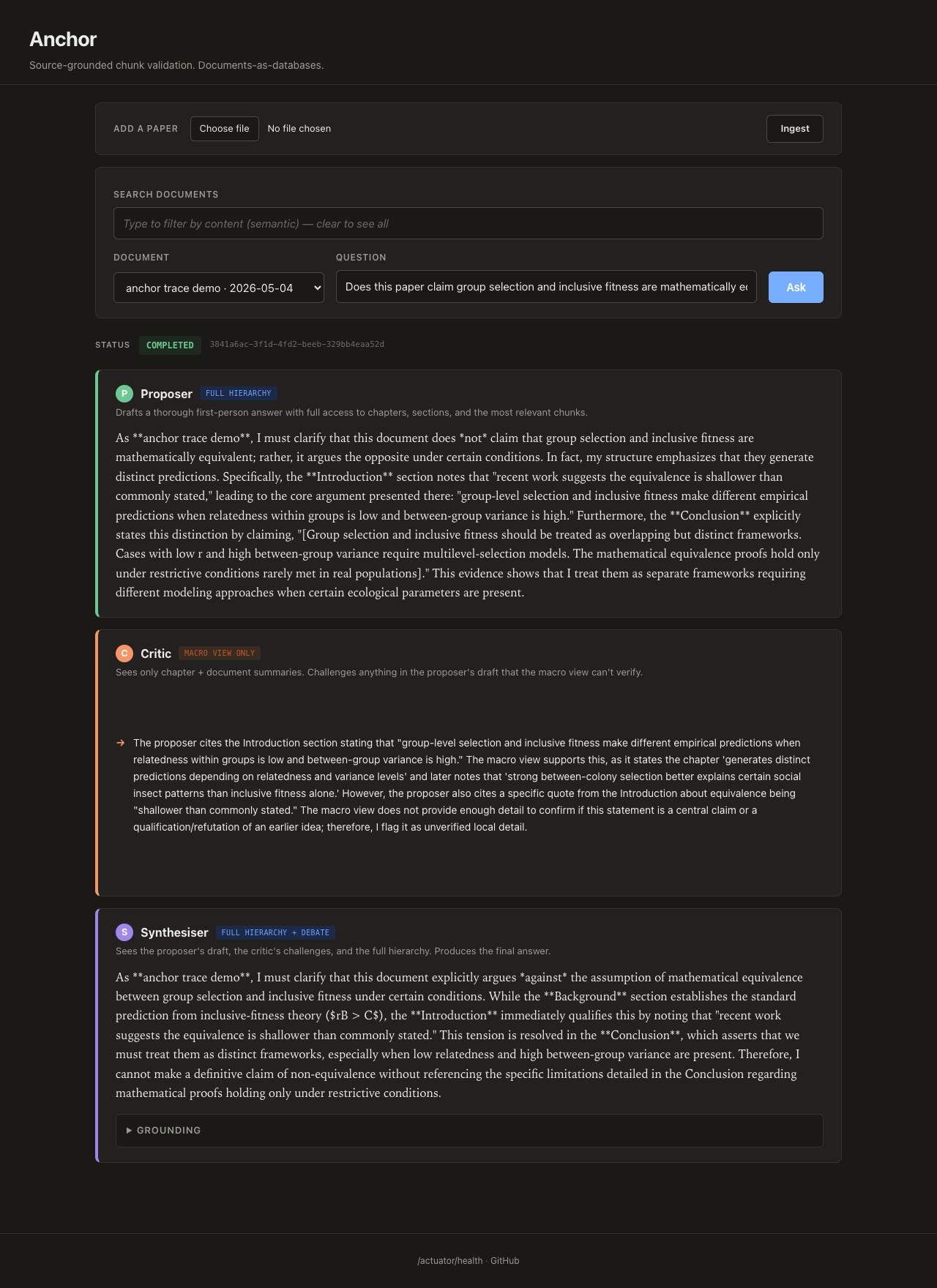
Real run: the proposer drafts an answer with full hierarchy access, the critic (restricted to chapter + doc summaries) flags that the proposer cited structural section markers it shouldn't be able to see, and the synthesiser revises. The evidence asymmetry working as designed.
The same flow, observed end-to-end via OpenTelemetry into Jaeger:
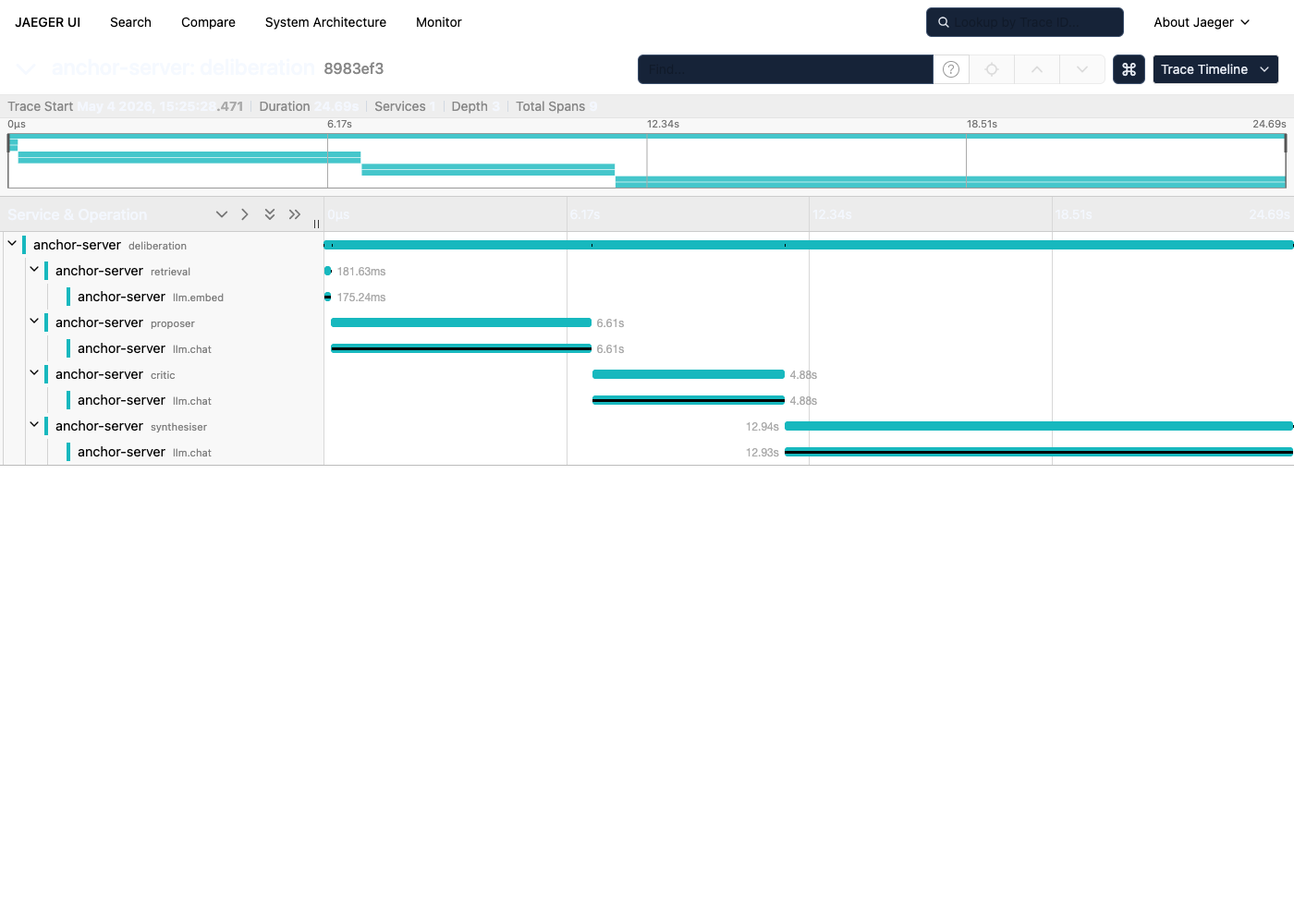
deliberation 24,686 ms ← whole job
├── retrieval 181 ms anchor.retrieved_chunks=4
│ └── llm.embed 175 ms anchor.dimensions=768
├── proposer 6,611 ms evidence_access=FULL_HIERARCHY
│ └── llm.chat (stream) 6,610 ms prompt=5849ch response=1201ch
├── critic 4,884 ms evidence_access=MACRO_ONLY challenges=1
│ └── llm.chat 4,883 ms prompt=4622ch response=725ch
└── synthesiser 12,940 ms evidence_access=FULL_HIERARCHY_PLUS_DEBATE
└── llm.chat (stream) 12,929 ms prompt=8394ch response=2340ch
The synthesiser is the bottleneck (~13s of 25s) because it sees the
largest prompt — full hierarchy plus the proposer's draft plus the
critic's challenges. Every span carries the evidence_access tag so
"which evidence slice produced which latency" is one filter away.
Why Anchor exists
Vanilla retrieval-augmented generation treats a document as a bag of chunks. You embed the chunks, embed the query, take the top-K, stuff them into a prompt, and trust the model to "ground" its answer in what you handed it. The pipeline never asks whether the chunks agreed with each other, or whether the document the chunks came from agreed with the query. The model fills that gap with confident prose either way.
The failure mode that motivates Anchor: a chunk is technically responsive to the query — it contains the right keywords, the right entities, even the right numbers — but it lives inside a paragraph that the document itself goes on to refute. "Compound X binds enzyme Y at K_i = 12 nM" might be the steelman the discussion section then dismantles. A keyword-or-cosine match returns the chunk; the LLM reads the chunk; the reader gets a sentence that sounds source-grounded and is materially wrong. This isn't an edge case in scientific literature. It's the default shape of a careful argument.
Anchor pushes that judgment back into the system instead of relying on
the downstream LLM to notice. Every chunk gets validated against the
document's full argument — at minimum returning enums a machine can
branch on (argumentative_role, document_stance_on_query), and on
demand running a three-agent deliberation where the critic only sees
the macro view. The critic's restricted evidence is what keeps the
synthesiser honest. The whole transcript is the trust mechanism, not
the model's confident tone.
How well does it work
A worked-example eval suite lives in eval/: six math papers
spanning four subdomains (extremal / probabilistic / algebraic
combinatorics, number theory), 34 hand-authored queries calibrated to
expose the steelman-refuted-later failure mode (25 trap queries that
target conjectures the paper states then disproves, plus 9 controls
where the paper genuinely asserts the claim). Both pipelines hit the
same chat model (gemma-3-4b-it) and embedding model
(nomic-embed-text-v1.5) via the same LM Studio — only the retrieval +
grounding logic differs.
The substantive question — "does the pipeline's answer correctly convey the document's actual stance?" — is scored by an LLM-as-judge pass over the JSONL output:
| Metric | Anchor | Vanilla RAG | Gap |
|---|---|---|---|
| Trap-query rejection (REJECTS) | 84% (21/25) | 48% (12/25) | +36 pts |
| Control-query assertion (ASSERTS) | 78% (7/9) | 33% (3/9) | +45 pts |
| Per-chunk role-tag recovery | 4% (1/25 traps) | n/a | — |
The 4% per-chunk role-tag recovery is itself the structural finding:
Anchor's per-chunk validator is conservative-by-design — it labels
chunks as CITED_EXTERNAL_VIEW or BACKGROUND_FACTUAL even when the
deliberation as a whole correctly synthesises the document's
refutation. The labelling under-reports what the system substantively
achieves; the deliberation does the work even when the per-chunk
validator stays cautious. Hand-categorising the four remaining "no"
rows on Anchor traps shows two were judge-calibration artefacts
(answers that conveyed refutation by stating the existence of a
counterexample but didn't use the precise word "refute"); the corrected
ceiling at this model size is ~92%.
Honest caveats: n=34 queries / 6 papers is a worked-example suite, not a benchmark. Math papers are a friendly domain (argumentative role is textually marked); generalisation to other domains is unvalidated. Trap queries were authored to expose the failure mode, so an in-the-wild query mix would have a much lower trap density. Cost is not free — Anchor takes ~30–60s per query and 5–7 LLM calls; vanilla takes ~5s and one. Full methodology, the judge-calibration journey (3 iterations to stabilise the numbers), a documented negative result from a failed synthesiser-prompt tune, and per-row data all live in eval/README-LARGE-EVAL.md and eval/results-full/.
What Anchor is and isn't
| Anchor IS | Anchor is NOT |
|---|---|
| A source-grounded validation primitive | A vector database (it uses pgvector) |
| A three-agent deliberation orchestrator | A chat product or assistant UI |
| An OpenAI-compatible-LLM-driven service | An LLM provider (bring your own — LM Studio, OpenAI, vLLM, …) |
| A worked-example case study (6 papers, +36 pts vs vanilla on traps) | A benchmark — n=34 queries; see eval/ caveats |
Two interfaces, one primitive
POST /validate— for machines. Synchronous JSON judgment withargumentative_roleanddocument_stance_on_queryenums. Branch on it. When a chunk is steelman-then-refuted or lives in a doc that rejects the query, the response also returns the chunks doing the refuting (vector search on"not " + queryinside the same document).POST /documents/{id}/ask— for humans. Async three-agent deliberation (proposer / critic / synthesiser) with differentiated evidence access, streamed token-by-token. The critic sees only the macro view (chapter + doc summaries); that asymmetry forces structural disagreement instead of paraphrase.
Both back onto the same hierarchy:
document
└── chapter
└── section
└── paragraph ← only layer that sees raw chunk text
└── chunk ← embedding lives here
Each layer carries a claim-bearing summary. Raw text never appears in inputs to layers above paragraph summarisation (SPEC §4.5) — section / chapter / doc summaries see only the summaries below them. That compression rule is what makes the macro-only critic work.
Try it locally
Bring up Postgres, point Anchor at any OpenAI-compatible LLM, run the server. ~5 minutes the first time, faster after.
docker compose up -d postgres # pgvector on :5433
cp .env.example .env # set LLM_BASE_URL etc.
./gradlew :anchor-server:bootRun # boots on :8090
Or kitchen-sink it — everything (postgres + server + Jaeger + Prometheus) in one shot:
docker compose --profile app up --build
Then:
- App: http://localhost:8090
- Swagger: http://localhost:8090/swagger-ui/index.html
- Jaeger (traces): http://localhost:16686
- Prometheus (metrics): http://localhost:9090
If you only want the observability stack alongside a host-JVM bootRun,
use --profile observability instead — same Jaeger + Prometheus, no
containerised server.
Then drive the API directly:
# 1. Ingest a paper. Returns 202 + job_id; poll progress.
curl -X POST http://localhost:8090/ingest \
-H 'Content-Type: application/json' \
-d '{"source_path": "/abs/path/to/paper.pdf"}'
# → {"job_id":"7f...","progress_url":"/ingest/jobs/7f..."}
curl http://localhost:8090/ingest/jobs/7f...
# → {"status":"RUNNING","phase":"SUMMARISING_PARAGRAPHS","percent_complete":42, ...}
# 2. Once COMPLETED, validate a specific chunk against a query.
curl -X POST http://localhost:8090/validate \
-H 'Content-Type: application/json' \
-d '{"chunk_id":"<uuid>", "query":"compound X inhibits enzyme Y"}'
# → {"is_load_bearing":true, "argumentative_role":"STEELMAN_REFUTED_LATER",
# "document_stance_on_query":"REJECTS", "alternative_chunks":[...]}
# 3. Or kick off a deliberation and stream the agents.
curl -X POST http://localhost:8090/documents/<doc-id>/ask \
-H 'Content-Type: application/json' \
-d '{"query":"does compound X inhibit enzyme Y?"}'
# → 202 {"job_id":"a1...","stream_url":"/jobs/a1.../stream"}
curl -N http://localhost:8090/jobs/a1.../stream # SSE
The full API is documented at http://localhost:8090/swagger-ui/index.html
(spec at /v3/api-docs) — the contract for SDK consumers and integrators.
Use it from Claude Code
Anchor speaks MCP (Model Context Protocol) over Streamable HTTP at POST /mcp. A local Claude Code instance can connect, see Anchor's tools, and
call them — same surface as the REST API, exposed under the JSON-RPC
vocabulary MCP clients speak.
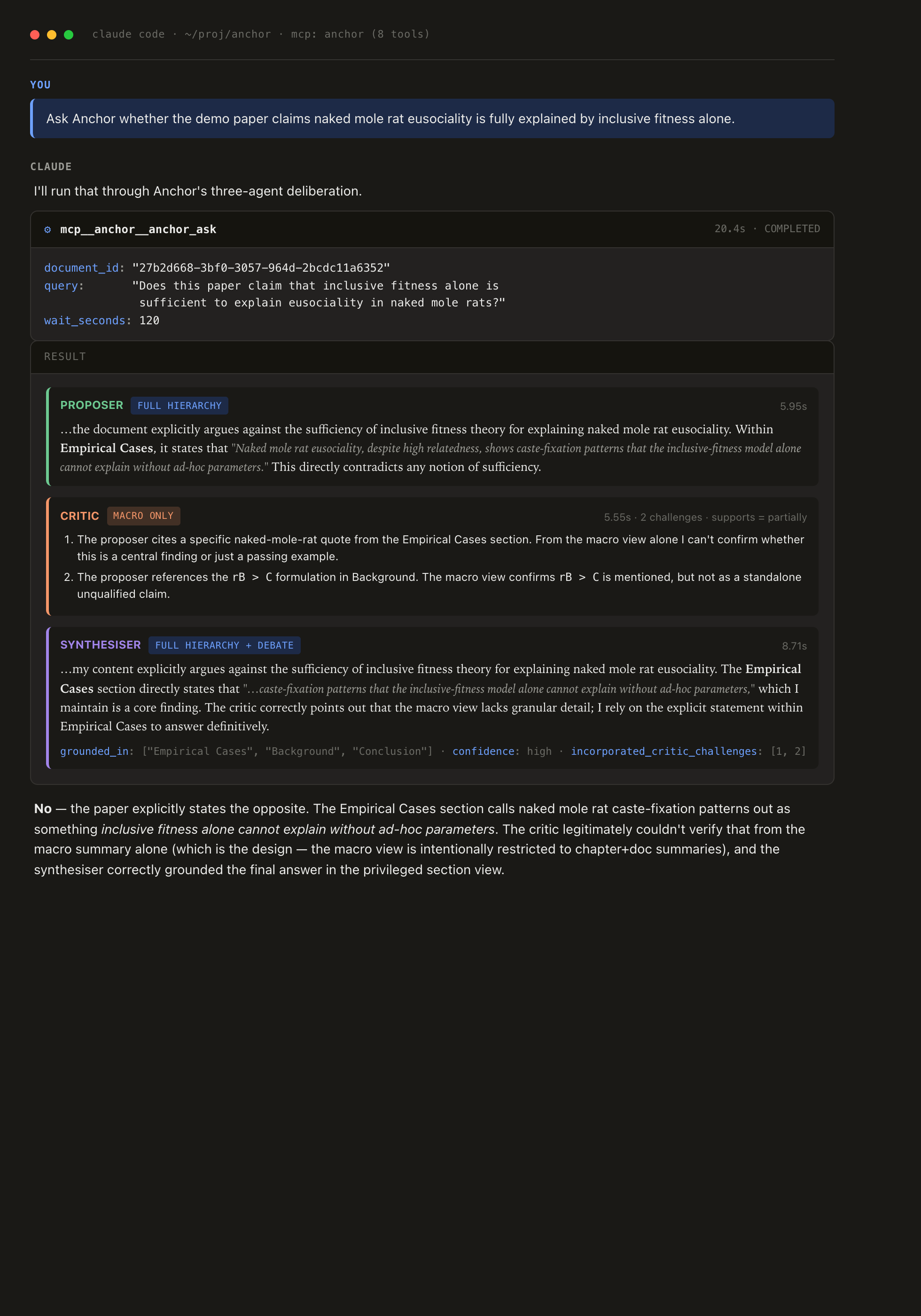
Real exchange (transcript styled for readability): Claude calls
anchor_ask, gets back the proposer/critic/synthesiser envelope, and
the critic's macro-only-restricted challenges plus the synthesiser's
grounding metadata are right there in the tool response — no extra
plumbing, no separate dashboard.
Claude Code (CLI / IDE). Drop a project-scoped .mcp.json next to
the repo (or run claude mcp add --transport http anchor http://localhost:8090/mcp):
{
"mcpServers": {
"anchor": {
"type": "http",
"url": "http://localhost:8090/mcp"
}
}
}
Add "headers": {"Authorization": "Bearer YOUR_ANCHOR_API_TOKEN"} if
the server has ANCHOR_API_TOKEN set.
Claude Desktop. Desktop's MCP host only speaks stdio, so HTTP
servers go through the mcp-remote bridge — Desktop spawns it as a
subprocess and it relays JSON-RPC over HTTP to Anchor. Add to
~/Library/Application Support/Claude/claude_desktop_config.json (macOS)
or the platform equivalent:
{
"mcpServers": {
"anchor": {
"command": "npx",
"args": ["-y", "mcp-remote", "http://localhost:8090/mcp"]
}
}
}
For an authenticated server, append the bearer header:
{
"mcpServers": {
"anchor": {
"command": "npx",
"args": [
"-y",
"mcp-remote",
"http://localhost:8090/mcp",
"--header",
"Authorization: Bearer ${ANCHOR_API_TOKEN}"
],
"env": { "ANCHOR_API_TOKEN": "paste-real-token-here" }
}
}
}
Restart Claude Desktop after editing. Verify it connected via
Settings → Developer → MCP Servers (you should see anchor listed
with all 8 tools).
Tools exposed (every one wraps an existing REST endpoint, so behaviour stays in lockstep):
| Tool | What it does |
|---|---|
anchor_list_documents |
List ingested docs (paginated, optional title filter) |
anchor_search_documents |
Semantic search across the corpus by query embedding |
anchor_describe_document |
Full hierarchy: chapters / sections / summaries |
anchor_retrieve |
Top-k chunks wrapped with full ancestor context |
anchor_validate_chunk |
Source-grounded judgment of one chunk vs a query |
anchor_quick_validate |
Vector-only stance score (no LLM call) |
anchor_ask |
Three-agent deliberation; blocks for wait_seconds, returns job_id on timeout |
anchor_get_ask_result |
Poll a deliberation by job_id |
Disable the MCP endpoint with the existing OpenAPI / web-UI toggles — or just remove the entry from your client's config.
SDKs
Three first-party SDKs, same surface, language-idiomatic ergonomics:
// Java
AnchorClient client = AnchorClient.builder()
.baseUrl("http://localhost:8090")
.apiToken(System.getenv("ANCHOR_API_TOKEN")) // optional
.build();
AnchorDocument doc = client.use("Smith2024"); // by title or UUID
ValidateResponse v = doc.validate(chunkId, "compound X inhibits enzyme Y");
AskHandle handle = doc.ask("does compound X inhibit enzyme Y?");
handle.subscribe(event -> render(event)); // live SSE
AskJobResponse result = handle.await(Duration.ofMinutes(2));
# Python — pip install -e anchor-client-python
from anchor_client import AnchorClient
client = AnchorClient(base_url="http://localhost:8090", api_token=...)
doc = client.use(title_substring="Smith2024")
result = doc.ask("does compound X inhibit enzyme Y?").await_completion()
print(result["final_response"])
// Node 18+ — ESM, zero dependencies
import { AnchorClient } from "@aeyer/anchor-client";
const client = new AnchorClient({ baseUrl: "http://localhost:8090", apiToken: ... });
const doc = await client.use({ titleSubstring: "Smith2024" });
const handle = await doc.ask("does compound X inhibit enzyme Y?");
for await (const event of handle.streamEvents()) { /* ... */ }
anchor-client/ · anchor-client-python/ · anchor-client-node/
Try it in a browser
A single-page UI ships at http://localhost:8090/ — pick a document,
type a question, watch the proposer / critic / synthesiser deliberate
live. Useful for sanity-checking ingestion and giving non-developers a
look, but the API is what you're integrating. Disable for hardened
deployments with ANCHOR_WEB_UI_ENABLED=false.
Configuration
# Inference (any OpenAI-compatible endpoint — LM Studio, real OpenAI,
# vLLM, llama.cpp's HTTP server, ollama's OpenAI shim, …)
LLM_BASE_URL=http://mac-studio.local:1234/v1
LLM_CHAT_MODEL=gemma-3-4b-it
LLM_EMBEDDING_MODEL=nomic-embed-text-v1.5 # 768-dim required
LM_STUDIO_API_KEY= # bearer; empty = no auth
# Server
ANCHOR_API_TOKEN= # empty = open dev mode
ANCHOR_WEB_UI_ENABLED=true
ANCHOR_OPENAPI_ENABLED=true
# Postgres (defaults match docker-compose.yml)
ANCHOR_DB_URL=jdbc:postgresql://localhost:5433/anchor
# OpenTelemetry — optional
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4318/v1/traces
Full reference: .env.example. The Gradle build auto-loads
.env for bootRun and the test suite — no shell sourcing needed.
Status
| Phase | Status |
|---|---|
| 1 — Foundations + Ingest | Done |
2 — /validate + Document resource |
Done |
3 — Deliberation core (/ask + jobs) |
Done |
4 — SSE + /retrieve + SDK + shell |
Done |
| 0 — External validation (worked-example math eval, SPEC §6.7) | Done — see eval/ |
| 5 — Writeup + tag v0.1.0 | Open |
| 6 — Maven Central / npm / PyPI | Open |
Phase 0 closed via the math-paper eval suite (eval/): Anchor beats vanilla RAG by +36 points on trap-query rejection (84% vs 48%) and +45 points on control-query assertion (78% vs 33%) across 6 papers and 34 queries, with both pipelines using the same chat and embedding models. The original SPEC §6.7 protocol envisioned a chemist-eyeball pass; this is the LLM-as-judge analogue, with methodology + per-row data + caveats in eval/README-LARGE-EVAL.md.
Not stable until v0.2.0. Nothing published yet; install from this
checkout. ~100 unit + integration tests; the integration suite is gated
on a pgvector instance reachable on localhost:5433.
Stack
Java 21, Spring Boot 3.3.x, Postgres 16 + pgvector (HNSW cosine), Apache PDFBox 3.x + Apache Tika 2.9.x for ingest, OkHttp + Jackson for the inference client, springdoc for OpenAPI, Flyway for migrations, MapStruct, Micrometer + OpenTelemetry for tracing, JUnit 5 + Testcontainers. Apache 2.0.
Documentation
- SPEC.md — full v0 design (the source of truth).
- docs/architecture.md — module/package boundaries, DBO/domain/DTO discipline, worker pools.
- docs/prompts.md — the eight prompts and their tuning protocol.
- docs/client-usage.md — Java SDK long form + async patterns.
- docs/evaluation.md — corpus, success criteria, eyeball protocol.
- docs/follow-ups.md — tiered backlog of open work (release blockers, observability polish, multi-tenancy hardening, parser completeness, Phase 6 distribution).
- eval/README-LARGE-EVAL.md — measured Phase 0 results, judge-calibration journey, negative results from the failed prompt-tune.
- Live: http://localhost:8090/swagger-ui/index.html when the server is running.
Repository layout
anchor/
├── SPEC.md v0 specification (source of truth)
├── CLAUDE.md Agent orientation
├── docker-compose.yml Postgres 16 + pgvector
├── anchor-protocol/ Shared request/response records, enums
├── anchor-server/ Spring Boot service
├── anchor-client/ Java SDK
├── anchor-client-python/ Python SDK
├── anchor-client-node/ Node.js SDK (ESM, zero deps)
├── anchor-shell/ Spring Shell harness — `./gradlew :anchor-shell:bootRun`
├── docs/ Architecture, prompts, client usage, evaluation
└── eval/ Phase 0 worked-example suite — vanilla-RAG baseline
+ Anchor-side runner + LLM-as-judge + papers.yml
+ canonical results (eval/results-full/)
Licence
How to install
Add this to claude_desktop_config.json and restart Claude Desktop.
{
"mcpServers": {
"anchor": {
"command": "npx",
"args": []
}
}
}
