Memstem
FreeNot checkedA standalone memory service that provides a unified, pull-based knowledge store for AI agents, enabling shared memory and skills across multiple AI clients via

About
A standalone memory service that provides a unified, pull-based knowledge store for AI agents, enabling shared memory and skills across multiple AI clients via MCP.
README
Unified memory and skill infrastructure for AI agents. One canonical knowledge store. Many AI clients. No version-fragility.
A central memory with stems reaching out to other systems, drawing their memories in.
If memstem helps you, please ⭐ the repo — there's no telemetry here, so stars are the only signal I have for whether to keep building this in the open.
What it is
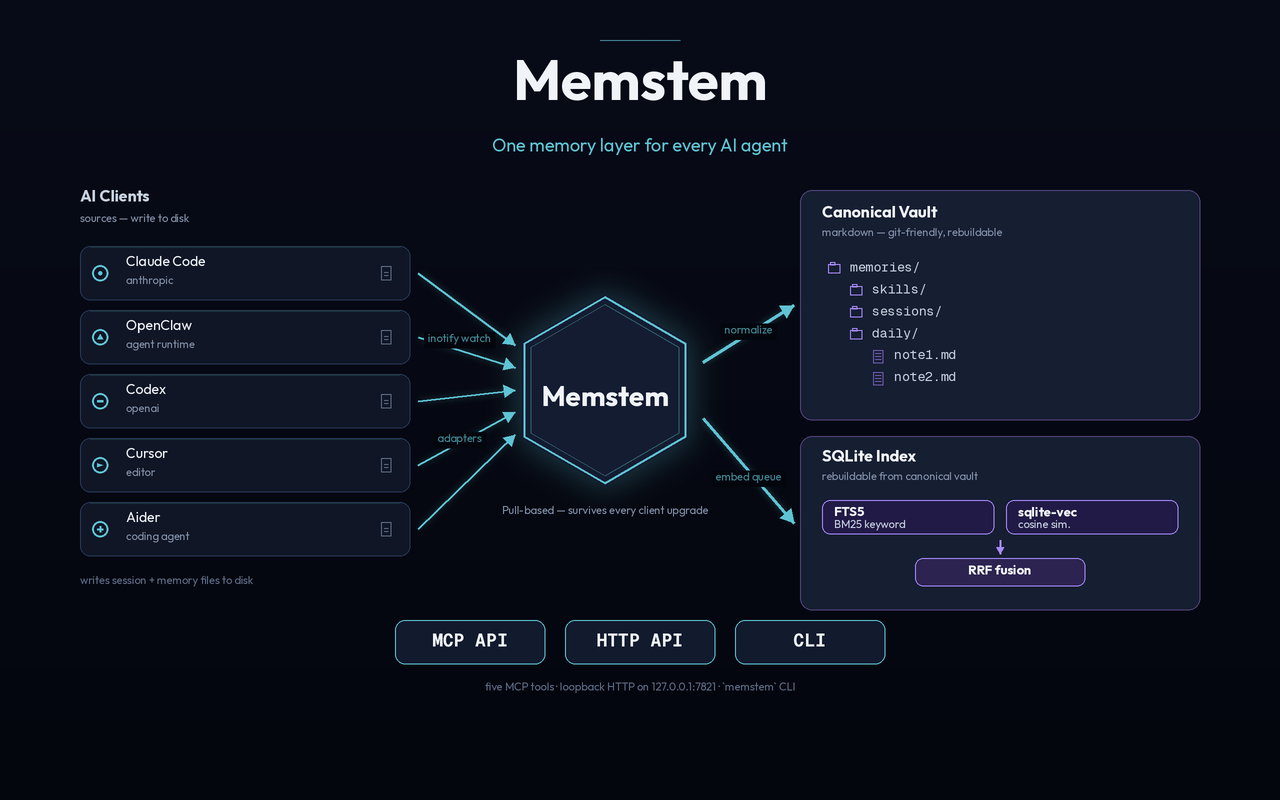
Memstem is a standalone memory service that acts as the single source of truth for memories and skills shared across multiple AI environments. Unlike traditional memory layers that you push to from each AI, Memstem pulls from the filesystem of each connected AI — so it's immune to upgrade churn in any of them.
Connect Claude Code, OpenClaw, and Codex today — adapters for Cursor, Aider, and more are on the roadmap. Memstem watches each system's session and memory files, ingests new content within seconds, and exposes one unified search API via MCP.
Why
Existing AI memory systems break when their host upgrades. Push-based hooks fail silently across version changes. Each AI has its own memory format, and there's no clean way to share knowledge across them.
Memstem solves this by:
- Pull-based ingestion via
inotify/ FSEvents filesystem watchers — no hooks, no push APIs to break - Markdown-canonical storage — files are the truth, the index is rebuildable
- Hybrid search — BM25 (FTS5) + cosine similarity (sqlite-vec) + reciprocal rank fusion
- Multi-AI adapters — pluggable per-system ingestion (Claude Code, OpenClaw, Codex, etc.)
- MCP-native API — every modern AI agent can call it
Architecture (one paragraph)
Markdown files in a structured tree are the canonical store. A SQLite database with FTS5 and sqlite-vec is the rebuildable index. A daemon watches each connected AI's filesystem and ingests deltas. An MCP server exposes search, get, and skill retrieval to clients. A hygiene loop runs inside the daemon — distilling sessions, judging duplicates, scoring importance, and building project records on configurable intervals.
See ARCHITECTURE.md for the full design and ROADMAP.md for the phase plan.
Status
v0.18.0 — actively developed, running in production.
Live on the maintainer's infrastructure, ingesting from multi-agent
OpenClaw, Claude Code, and Codex in real time. The 0.13 line added the
recall-quality stack (cross-encoder reranking + MMR, multimodal
embeddings, a validated fully self-hosted Qwen3 recall setup); 0.14
through 0.16 were three reliability batches from a full-codebase
review — durability, concurrency, failure visibility, embed-queue
claim/lease, and dedup-judge correctness. 0.17 added security hardening
(request-edge clamps, reserved _-path rejection, optional HTTP
bearer-token auth) and the first publication to PyPI; 0.18 adds
source-deletion tombstones — deleting an authored source file in a
connected agent's workspace removes its memory from search (ADR 0026).
See CHANGELOG.md for the release-by-release history.
Shipping:
- Hybrid search (FTS5 BM25 + sqlite-vec cosine, merged with RRF) over a markdown-canonical vault. Index is rebuildable from the files.
- Five MCP tools (
memstem_search,_get,_list_skills,_get_skill,_upsert) plus a co-hosted local HTTP API on127.0.0.1:7821for first-party clients (CLI tools, future editor extensions), with optional bearer-token auth for non-loopback deployments. - Pluggable embedders — Ollama (local default), OpenAI, Gemini, Voyage, or
any OpenAI-compatible server — selectable via
_meta/config.yaml. For a self-hosted, no-cloud setup the recommended embedder is Qwen3-Embedding-8B (4096-dim, instruction-tuned); see Embedding provider. Always-on embed queue with retry/backoff and idle-timeout self-exit. - Cross-encoder reranking + MMR — opt-in recall-quality
pass that re-orders hybrid-search candidates with an LLM reranker and
diversifies near-duplicates with MMR, wired into config, the daemon, MCP, and
CLI (
--rerank,--mmr,--rerank-top-n). Off by default; pair it with a self-hosted Gemma/Qwen reranker for zero per-query cloud cost. See Search & reranking. - Derived records —
memstem hygiene distill-sessionsproducestype: distillationcompanion records for meaningful sessions, andmemstem hygiene project-recordsaggregates per-project-tag sessions intotype: projectrollups. Both are CLI-driven, idempotent, opt-in (NoOp default; pluggable OpenAI / Ollama summarizer). Direct fix for "the project where we did X" queries that today fail to surface project work that exists in the vault. See docs/distillation-verification.md. - In-daemon hygiene loop —
memstem daemonruns the four hygiene stages (distill-sessions, dedup-judge, importance, project-records) as background tasks alongside the watchers and embed workers, each on its own configurable interval with per-stage locking and failure isolation.GET /healthexposes per-stagelast_runtimestamps for fleet monitoring; setloop_enabled: falseon multi-tenant hosts where the customer hasn't authorized LLM spend. See ADR 0023. - OpenAI-compatible LLM backends for hygiene — the
dedup judge and summarizer speak the OpenAI chat-completions protocol,
so dedup judging, distillation, and project-records can run against a
self-hosted vLLM / TGI / LM Studio / LiteLLM endpoint via a
base_urloverride — no per-customer cloud billing. The audit log and provenance honestly label which service produced each verdict (openai:gpt-…for OpenAI Inc.,openai-compat:gemma-…for a self-hosted endpoint). - Codex adapter — third filesystem adapter (after
Claude Code and OpenClaw), watching
~/.codex/sessions|skills|memories; enabled by default and no-ops silently on hosts without Codex. Codex sessions group by project tag alongside Claude Code's. See ADR 0022. - Source-deletion tombstones — deleting an authored source file
(
memory,skill, ordailylog) in a connected agent's workspace removes the corresponding memory from search. A reconcile-time source-liveness sweep sets adeleted_atmarker (filtered from search likevalid_to/deprecated_by, and recoverable viainclude_deleted), cleared automatically if the source is restored. Session logs and generated records (distillations, project rollups) are never affected, and a vanished workspace mount is skipped rather than mass-tombstoned. See ADR 0026. - Security hardening — request-edge size/value clamps, rejection of
reserved
_-prefixed vault paths, optional HTTP bearer-token auth for non-loopback deployments, and Gemini API keys sent via request header rather than query string. - Post-cleanup operator workflow —
memstem hygiene verifyis a single read-only command that summarizes vault state after a cleanup + backfill sweep: per-type counts, distillation coverage, undistilled-eligible sessions remaining, dedup / noise findings cleanup-retro would still flag, open skill review tickets, and parser/validation skips. Optional--json-outemits a machine-readable payload for CI / monitoring. Replaces ad-hoc SQLite inspection. See the post-cleanup playbook in docs/operations.md. - Explicit ranking policy —
SearchConfig.type_biasmultiplies each result's score by a small per-type weight so default search clearly prefers curated/derived records (distillation 1.10, memory/skill/project 1.05) over raw conversational sessions (0.85). Bounds are intentionally tight ([0.85, 1.10]) — the bias breaks ties without overriding relevance. Tunable per-vault in_meta/config.yaml; an empty mapping recovers pre-0.10 behaviour. - Quality pipeline — write-time noise filter, exact-body hash dedup (Layer 1), TTL tagging for transient kinds, boot-echo hash filter — keeps the vault from being polluted by AI-session firehose.
memstem authfor persistent embedder API keys (~/.config/memstem/secrets.yaml, mode 0600), so cron, PM2, systemd, and headless servers don't need per-shell exports.- Secret handling (architecture and policy locked, implementation
in phases). Memstem is being extended with a
SecretBackendinterface, agent-sidevault.put/vault.gettools, system-prompt guidance, and an ingest-time regex pack that redacts known-format secrets to vault placeholders before they enter the index. Scope and limits are documented up front so customers know what Memstem will and will not commit to — it is not a guaranteed secret scanner. See docs/secrets.md for the full responsibility boundary and shipping-status table. - Operational tooling —
memstem init,doctor,connect-clients(idempotent wiring into~/.claude.jsonand each OpenClaw agent'sopenclaw.json),migrate(FlipClaw → Memstem one-shot), a one-lineinstall.sh, and a 15-second e2e smoke test (scripts/e2e-smoke.sh).
Cross-platform CI runs Linux (gating) plus macOS and Windows
(experimental, continue-on-error: true — sqlite-vec needs
enable_load_extension, which actions/setup-python's macOS build
doesn't ship; native Windows is WSL2-only by design for v0.x).
1,400+ tests passing. See ROADMAP.md for what's
next.
Quickstart
The full one-liner. Installs everything (memstem, Ollama, embedding model), scaffolds the vault, imports your existing Claude Code + OpenClaw memory, wires Memstem into Claude Code, and starts the daemon under PM2:
curl -fsSL https://raw.githubusercontent.com/Memstem/memstem/main/scripts/install.sh | bash -s -- \
--yes --connect-clients --migrate --migrate-no-embed --start-daemon
The default uses Ollama (local, no API key, no network call). To install with a cloud embedder in one go:
# OpenAI (text-embedding-3-large at 3072 dimensions)
curl -fsSL https://raw.githubusercontent.com/Memstem/memstem/main/scripts/install.sh | bash -s -- \
--yes --embedder openai --openai-key "$OPENAI_API_KEY" \
--connect-clients --migrate --start-daemon
# Or Voyage / Gemini — same shape:
# --embedder voyage --voyage-key "$VOYAGE_API_KEY"
# --embedder gemini --gemini-key "$GEMINI_API_KEY"
Picking --embedder openai|gemini|voyage implies --no-ollama (cloud doesn't need a local daemon). The key gets stored via memstem auth set <provider>, so cron, PM2, and fresh shells all pick it up afterward without per-shell exports.
The --migrate-no-embed flag is the practical default on a CPU-only Ollama box: it imports records to vault + FTS5 in minutes instead of hours. After it returns:
memstem search "what did we decide about pricing" # FTS5 hits work immediately
pm2 logs memstem --lines 20 # watch ingestion + embed worker
memstem doctor # `Embed queue: N pending` shows backfill progress
Embedding is always queued rather than inline (see ADR 0009): the migrate finishes in seconds and the daemon's embed worker drains the queue at its own pace. On CPU-only Ollama that means semantic search becomes "good" over an hour or two; on the API providers above it's done in seconds.
Manual install if you'd rather not pipe a script:
pipx install memstem # or: pip install memstem
ollama pull nomic-embed-text # 768-dim local embedder
memstem init ~/memstem-vault # interactive wizard
memstem migrate --apply # one-shot history import
memstem connect-clients # patch settings + CLAUDE.md
memstem doctor # verify
memstem daemon # ingest + watch
On macOS, use a Homebrew or pyenv Python — the system Python ships a SQLite that can't load the sqlite-vec extension.
The full install reference — every installer flag, API-key handling, the macOS detail, and exactly what connect-clients edits — is in docs/install.md.
Querying from an agent
Once memstem connect-clients has run, an MCP-aware client (Claude Code, etc.) sees five tools:
| Tool | Purpose |
|---|---|
memstem_search |
Hybrid (FTS5 + vector) search across the vault |
memstem_get |
Fetch a memory by id or vault path |
memstem_list_skills |
List skills, optionally filtered by scope |
memstem_get_skill |
Fetch a skill by title |
memstem_upsert |
Create or update a memory record |
See docs/mcp-api.md for the full schema.
Every search runs in parallel down two paths and is merged with Reciprocal Rank Fusion, so exact-keyword hits and semantic neighbours both surface in one ranked list:

Configuration
~/memstem-vault/_meta/config.yaml controls embedding, search, and adapters. The wizard writes a sensible default; common edits:
Embedding provider — pick one
Memstem ships several providers. Default is local Ollama (zero-config, no API key). For a high-quality self-hosted setup with no cloud API, the recommended embedder is Qwen3-Embedding-8B (see the self-hosted block below). Switch by editing the embedding: block (then memstem reindex so existing vectors get redone against the new provider).
# Default — local, no API key
embedding:
provider: ollama
model: nomic-embed-text
dimensions: 768
# Google Gemini — Matryoshka shortening lets you keep any dim you want
# (768 = same as Ollama, no reindex when switching from Ollama default).
embedding:
provider: gemini
model: gemini-embedding-2-preview # default; ~20% recall over -001, 8k context
api_key_env: GOOGLE_API_KEY
dimensions: 768 # 768 / 1536 / 3072 — Matryoshka truncates the native 3072d
Pin model: gemini-embedding-001 if you'd rather have the production-stable predecessor (the "preview" label means Google may change behavior; new-RAG quality vs API stability is your call).
# OpenAI — or any OpenAI-compatible endpoint (Together, Mistral, Groq, vLLM, LM Studio)
embedding:
provider: openai
model: text-embedding-3-small
api_key_env: OPENAI_API_KEY
dimensions: 1536
# base_url: https://api.together.xyz/v1 # for OpenAI-compatible providers
# Voyage — Anthropic's recommended embedding partner; tops retrieval benchmarks
embedding:
provider: voyage
model: voyage-3
api_key_env: VOYAGE_API_KEY
dimensions: 1024
# Recommended self-hosted (no cloud API) — Qwen3-Embedding-8B on vLLM.
# Instruction-tuned 4096-dim retriever, served over the OpenAI-compatible path
# (point base_url at your own server). Pair with the query_instruction below and
# a self-hosted reranker (see "Search & reranking") for the full no-cloud stack.
embedding:
provider: openai # OpenAI-compatible client
model: qwen3-text-embed # the name your vLLM serves
base_url: http://your-vllm-host:8000/v1
api_key_env: OPENAI_API_KEY # any non-empty token; vLLM ignores it
dimensions: 4096
query_instruction: "Given a search query, retrieve relevant memories, notes, and documents that answer it"
API keys are read from environment variables named in api_key_env — they never land in the vault. embedding.workers (default 2) and embedding.batch_size (default 8) tune the queue throughput; CPU Ollama is happiest at 1 worker, API providers tolerate 4+.
Search & reranking (recall quality)
Hybrid search (BM25 + vector, merged with RRF) works out of the box. For higher precision, enable the reranker + MMR pass: it re-orders the top candidates with an LLM and diversifies near-duplicates. Off by default — opt in per vault:
search:
mmr_lambda: 0.5 # 0 = max diversity, 1 = pure relevance
rerank_top_n: 15 # candidate pool the reranker re-scores
reranker:
enabled: true
provider: openai # OpenAI-compatible — also works against a self-hosted vLLM box
model: gemma-4-e4b-it # or gpt-4o-mini, qwen2.5:7b, ...
base_url: http://your-vllm-host:8000/v1
api_key_env: OPENAI_API_KEY
Per-query overrides: memstem search "q" --rerank --mmr 0.5 --rerank-top-n 15
(and --no-rerank to skip). Together with the Qwen3 embedder + query_instruction
above, this is the validated fully self-hosted recall stack — no per-query cloud
cost. For picking the reranker LLM, see
recall-quality model recommendations.
Adapters
embedding:
provider: ollama
model: nomic-embed-text
base_url: http://localhost:11434
dimensions: 768
adapters:
openclaw:
agent_workspaces:
- { path: ~/assistant, tag: assistant }
- { path: ~/support-agent, tag: support }
shared_files:
- ~/assistant/RULES.md
claude_code:
project_roots:
- ~/.claude/projects
extra_files:
- ~/.claude/CLAUDE.md
Run memstem doctor after edits to verify every configured target exists and the embedder is reachable.
Distillation + project records
Two hygiene commands turn raw session transcripts and per-project session sets into retrieval-shaped derived records. Both are CLI-driven, idempotent, and opt-in — NoOp is the install-time default, you opt into a real summarizer explicitly.
# One-shot backfill at cutover (or any time you want to refresh):
memstem auth set openai sk-...
memstem hygiene distill-sessions --backfill --provider openai --apply
memstem hygiene project-records --provider openai --apply
# Routine refresh (post-backfill):
memstem hygiene distill-sessions --provider openai --apply
memstem hygiene project-records --provider openai --apply
What you get:
- Session distillations at
vault/distillations/<source>/<session_id>.md— one paragraph + structured Key entities / Deliverables / Decisions / Status sections per session. Provenance always points back to the source transcript. - Project records at
vault/memories/projects/<slug>.md— one per Claude Code project tag with ≥2 sessions. Canonical project name extracted from the work itself, accumulated decisions, link map.
Both can also run with Ollama (--provider ollama, default model
qwen2.5:7b) for local-only setups. See
docs/distillation-verification.md
for the full operator workflow (dry-run, quality spot-check, eval
diff, manual override) and
docs/recall-models.md for the model
recommendations + cost expectations.
Verifying it works
Two complementary commands cover "is the install healthy?" and "is the vault state right after a cleanup + backfill sweep?".
memstem doctor is the install-level check — Python, vault, index,
embedder, and the configured adapter targets all reachable:
$ memstem doctor
Memstem doctor (vault=/home/ubuntu/memstem-vault):
✓ Python 3.11
✓ memstem 0.18.0
✓ Vault: /home/ubuntu/memstem-vault
✓ Config: /home/ubuntu/memstem-vault/_meta/config.yaml
✓ Index opens cleanly
✓ Ollama at http://localhost:11434 (nomic-embed-text) (768 dims)
✓ OpenClaw workspace: /home/ubuntu/assistant (tag=assistant)
✓ Claude Code root: /home/ubuntu/.claude/projects
All checks passed.
memstem hygiene verify is the operator-level check — vault state
after cleanup-retro + distill-sessions --backfill. Read-only,
safe on production. Reports total memories, per-type breakdown,
distillation coverage, dedup / noise findings still detectable,
open skill review tickets, and any parser/validation skips
encountered during the walk. --json-out writes the same payload as
JSON for CI / monitoring scrapers:
$ memstem hygiene verify
============================================================
MEMSTEM VERIFY
============================================================
Vault: /home/ubuntu/memstem-vault
Total memories: 1722
By type:
type total deprecated valid_to
--------------------------------------------------
session 665 1 1
memory 546 229 2
distillation 224 0 0
skill 193 0 0
daily 80 0 0
project 14 0 0
Cleanup state:
Deprecated records: 230
Records with valid_to: 3
Active dedup collision groups: 6
Active dedup → would deprecate: 11
Active dedup skill groups (review): 6
Noise drops still detectable: 0
Noise transients still detectable: 1
Skill review tickets open: 6
Derived records:
Sessions covered by distillation: 224
Undistilled eligible sessions left: 1
Parser/validation skips during scan: 0
The full operator playbook (run cleanup, run backfill, run verify, interpret findings, resolve skill review tickets, tune ranking) is in docs/operations.md — Post-cleanup operator playbook.
Platform support
| OS | Support | Notes |
|---|---|---|
| Linux | ✅ Tested | Primary development platform. CI gates merges on Python 3.11 + 3.12. |
| macOS | ⚠️ Supported, not CI-gated | watchdog uses FSEvents and the daemon runs. The CI runner's actions/setup-python ships a Python without enable_load_extension, which sqlite-vec needs, so macOS jobs run as continue-on-error: true for visibility. A user-installed Python (e.g. brew install [email protected]) has extension support enabled and works. |
| Windows | ❌ Use WSL2 | Native Windows runs in CI for visibility (continue-on-error: true) but is not supported. Run Memstem inside WSL2; native PowerShell support is on the roadmap. |
Documentation
- Architecture — system design and rationale
- Roadmap — release plan (Phases 1–5)
- Install guide — installer flags, API keys, macOS notes,
connect-clientsdetails - Operations — production smoke test, post-cleanup operator playbook, ranking-policy reference
- Frontmatter spec — the markdown schema
- MCP API — tool definitions
- Decisions — Architecture Decision Records
- Distillation + project records — operator playbook — how to run the new derived-record commands and verify quality
- Recall-quality model recommendations — picking the right LLM for rerank / HyDE / dedup / summarization with cost expectations
- Recall eval results — measured before/after data on the recall-quality features
License
MIT — see LICENSE.
Acknowledgments
Memstem builds on ideas from:
- basic-memory — markdown + wikilinks pattern
- doobidoo/mcp-memory-service — sqlite-vec hybrid retrieval reference
- Karpathy's LLM Wiki — index/log pattern
- Graphiti — bi-temporal facts
- Anthropic memory tool — abstract memory interface
Install Memstem in Claude Desktop, Claude Code & Cursor
unyly install memstemInstalls into Claude Desktop, Claude Code, Cursor & VS Code — handles npx, uvx and build-from-source repos for you.
First time? Get the CLI: curl -fsSL https://unyly.org/install | sh
Or configure manually
Run in your terminal:
claude mcp add memstem -- uvx memstemFAQ
Is Memstem MCP free?
Yes, Memstem MCP is free — one-click install via Unyly at no cost.
Does Memstem need an API key?
No, Memstem runs without API keys or environment variables.
Is Memstem hosted or self-hosted?
Self-hosted: the server runs locally on your machine via the install command above.
How do I install Memstem in Claude Desktop, Claude Code or Cursor?
Open Memstem on unyly.org, pick your client tab (Claude Desktop, Claude Code, Cursor) and press Install — the config is generated automatically, no JSON editing.
Related MCPs
Fetch
Web content fetching and conversion for efficient LLM usage.
AWS KB Retrieval
Retrieval from AWS Knowledge Base using Bedrock Agent Runtime.
 by modelcontextprotocol
by modelcontextprotocolSpring AI MCP Server
Provides auto-configuration for setting up an MCP server in Spring Boot applications.
llm-analysis-assistant
A very streamlined mcp client that supports calling and monitoring stdio/sse/streamableHttp, and can also view request responses through the /logs page. It also
 by xuzexin-hz
by xuzexin-hzCompare Memstem with
Not sure what to pick?
Find your stack in 60 seconds
Author?
Embed badge for your README
Browse similar
All ai MCPs